
最新刊期
卷 29 , 期 10 , 2025
- “在遥感图像融合领域,生成对抗网络技术展现出巨大潜力,为提升图像精度提供新方案。”
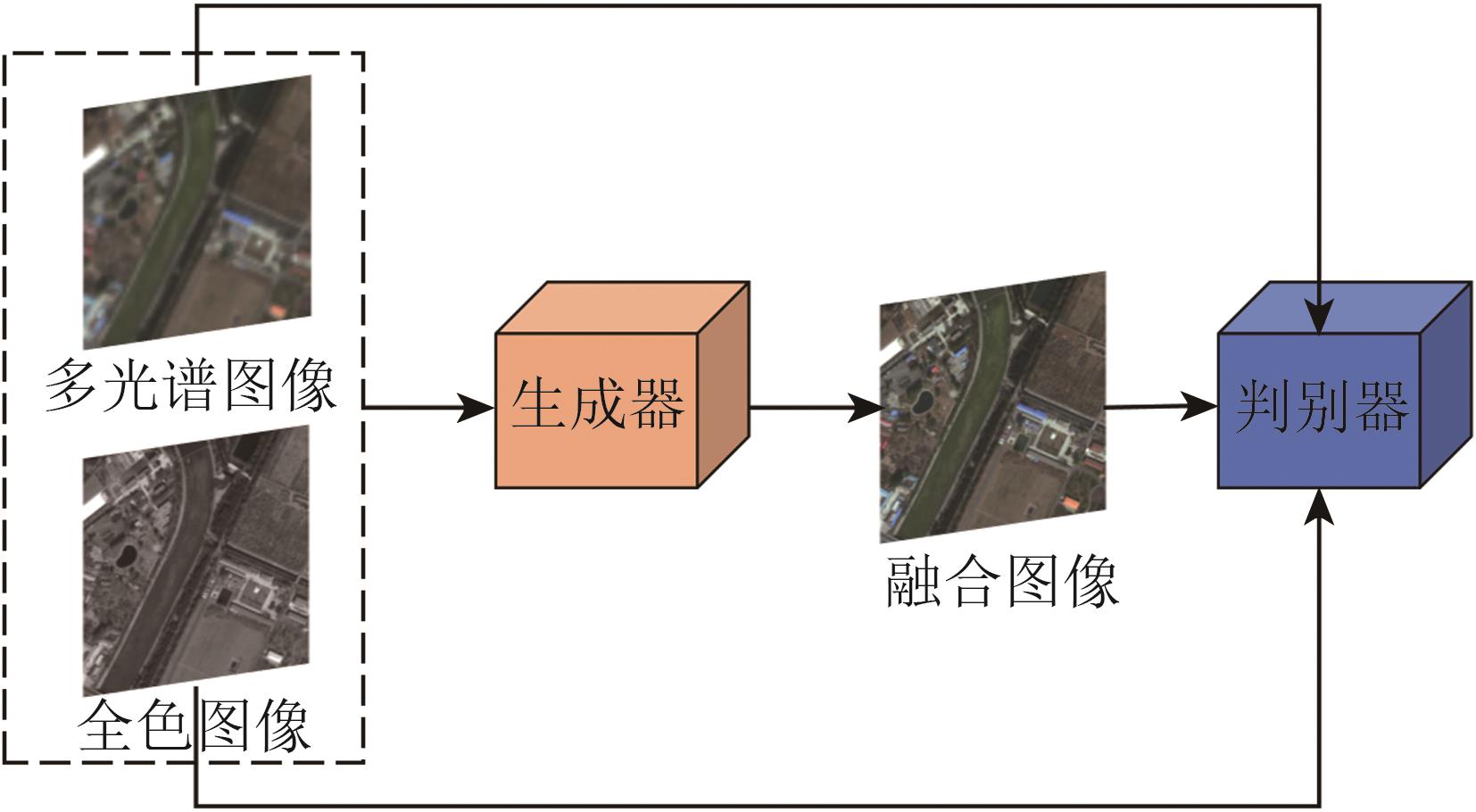 摘要:Remote sensing image fusion, as an important branch of data fusion, has attracted considerable attention in recent years. Images with high spatial and spectral resolutions can be generated by fusing remote sensing data from different sources, improving the ability to capture detailed information about ground objects. In the field of remote sensing image processing, the application of Generative Adversarial Networks (GANs) has developed rapidly, demonstrating significant advantages. This paper starts by introducing traditional remote sensing image fusion methods, followed by an analysis of GAN-based fusion techniques, with a detailed explanation of GAN’s applications in tasks such as pan-sharpening and hyperspectral pan-sharpening.Although traditional remote sensing image fusion methods can improve either spatial or spectral resolution to some extent, they often introduce spectral distortions, limiting their effectiveness. In recent years, various deep learning-based image fusion models have emerged. Among them, GANs, with their unique adversarial training mechanism, have demonstrated a remarkable ability to generate fused images that effectively balance spatial and spectral information while significantly reducing distortion. Numerous GAN-based remote sensing image fusion models, which leverage multiscale feature extraction, separate processing of spectral and spatial information, and optimized adversarial losses to substantially enhance the quality of the fused images, have been proposed. GANs are especially suitable for unsupervised and semisupervised learning, enabling the generation of high-quality fused images without reference images and thus addressing the common issue of the lack of reference data in remote sensing.This study analyzes common architectures of GANs used in multisource image fusion, including single-generator—double-discriminator, multigenerator—single-discriminator, multigenerator—multidiscriminator, and conditional GAN architectures. These architectures, using different training strategies, effectively handle a range of task scenarios. This study also explores the application of GANs in remote sensing image fusion. In the pan-sharpening task, GAN-based models not only improve spatial resolution but also enhance the fidelity of image details while preserving spectral information. Similarly, GANs show great potential in hyperspectral pan-sharpening, especially when combined with super-resolution techniques and adversarial learning, allowing for the effective fusion of multisource images and generating high-resolution multispectral and hyperspectral images. This paper discusses the importance of loss functions such as adversarial loss, spectral loss, and perceptual loss in GAN training, all of which ensure balanced optimization across different dimensions of the fused images.Finally, this paper summarizes the current state of GAN-based remote sensing image fusion methods and explores future research directions, including the integration of data- and model-driven approaches. It also expands on the challenges of generalization and computational complexity of GAN models in various remote sensing applications, proposing potential avenues for further optimization.关键词:remote sensing image;multi-source data fusion;deep learning;Generative Adversarial Network;pan-sharpening;multispectral image;hyperspectral image447|183|0更新时间:2025-12-17
摘要:Remote sensing image fusion, as an important branch of data fusion, has attracted considerable attention in recent years. Images with high spatial and spectral resolutions can be generated by fusing remote sensing data from different sources, improving the ability to capture detailed information about ground objects. In the field of remote sensing image processing, the application of Generative Adversarial Networks (GANs) has developed rapidly, demonstrating significant advantages. This paper starts by introducing traditional remote sensing image fusion methods, followed by an analysis of GAN-based fusion techniques, with a detailed explanation of GAN’s applications in tasks such as pan-sharpening and hyperspectral pan-sharpening.Although traditional remote sensing image fusion methods can improve either spatial or spectral resolution to some extent, they often introduce spectral distortions, limiting their effectiveness. In recent years, various deep learning-based image fusion models have emerged. Among them, GANs, with their unique adversarial training mechanism, have demonstrated a remarkable ability to generate fused images that effectively balance spatial and spectral information while significantly reducing distortion. Numerous GAN-based remote sensing image fusion models, which leverage multiscale feature extraction, separate processing of spectral and spatial information, and optimized adversarial losses to substantially enhance the quality of the fused images, have been proposed. GANs are especially suitable for unsupervised and semisupervised learning, enabling the generation of high-quality fused images without reference images and thus addressing the common issue of the lack of reference data in remote sensing.This study analyzes common architectures of GANs used in multisource image fusion, including single-generator—double-discriminator, multigenerator—single-discriminator, multigenerator—multidiscriminator, and conditional GAN architectures. These architectures, using different training strategies, effectively handle a range of task scenarios. This study also explores the application of GANs in remote sensing image fusion. In the pan-sharpening task, GAN-based models not only improve spatial resolution but also enhance the fidelity of image details while preserving spectral information. Similarly, GANs show great potential in hyperspectral pan-sharpening, especially when combined with super-resolution techniques and adversarial learning, allowing for the effective fusion of multisource images and generating high-resolution multispectral and hyperspectral images. This paper discusses the importance of loss functions such as adversarial loss, spectral loss, and perceptual loss in GAN training, all of which ensure balanced optimization across different dimensions of the fused images.Finally, this paper summarizes the current state of GAN-based remote sensing image fusion methods and explores future research directions, including the integration of data- and model-driven approaches. It also expands on the challenges of generalization and computational complexity of GAN models in various remote sensing applications, proposing potential avenues for further optimization.关键词:remote sensing image;multi-source data fusion;deep learning;Generative Adversarial Network;pan-sharpening;multispectral image;hyperspectral image447|183|0更新时间:2025-12-17 - “动物遥感与遥测技术在野生动物监测和保护、精准畜牧等领域取得新进展,为动物行为研究提供新视角。”
 摘要:Animal remote sensing and telemetry aim to monitor behavior, movement, and health while minimizing disturbance to individuals and populations. Using satellites, Unmanned Aerial Vehicles (UAVs), radar, acoustic tags, depth cameras, and related modern sensors, these approaches provide multiscale, non-contact observations that support research and management in wildlife conservation, precision livestock farming, and smart fisheries. This review synthesizes recent progress across wild and domesticated animals and clarifies outstanding challenges and opportunities. We first map the field’s development through literature analysis to trace publication trends, leading contributors, and evolving keywords, situating animal remote sensing at the intersection of ecology, geospatial science, animal science, and field-based observation. For wildlife, environment-linked indicators derived from optical and microwave remote sensing (e.g., vegetation indices, sea-surface temperature and height, and ocean color) help explain habitat selection, distribution patterns, and resource suitability, while direct detection with very-high-resolution satellite imagery, aerial photography, and UAV campaigns enables species identification and population estimation over broad extents. Telemetry integrating GPS and inertial sensors, accelerometry, and acoustic systems reveals migration timing, movement ecology, and space-use strategies in birds, terrestrial mammals, and marine species; complementary observations from weather radar networks and passive acoustics capture movements at regional to basin scales. For domesticated animals, non-contact morphometrics, body weight and body-condition scoring, individual identification, and herd distribution and grazing analyses are increasingly achieved with camera and depth sensing. Thermal infrared, millimeter-wave radar, and related biosignal approaches enable contact-free monitoring of temperature, respiration, cardiac activity, and rumination, informing health surveillance and precision management. Across platforms, modern data-processing pipelines—including machine learning for detection, re-identification, and counting—improve accuracy and scalability, while multi-source fusion links animal trajectories with dynamic environmental layers to uncover behavioral drivers and anticipate risk. Despite rapid progress, several challenges persist. There are mismatches between animal movement scales and sensor spatial or temporal resolution; limited sample sizes and label scarcity; dataset bias, domain shift, and fragile model generalization across regions, seasons, backgrounds, and sensor types; occlusion and clutter in complex habitats; and power, weight, and endurance constraints on tags and platforms. Ethical considerations around animal welfare, data governance, and potential disturbance also require explicit assessment. In addition, long-term monitoring demands robust calibration, cross-platform harmonization, and sustainable cost models to ensure continuity and comparability across programs and regions. We also summarize platform-specific error sources and validation practices, including annotation quality, cross-sensor co-registration, geolocation accuracy, and sample representativeness, to guide rigorous study design and reporting. We outline promising directions to address these gaps: miniaturized, energy-efficient tags and lower-cost sensors; higher-revisit imaging constellations and agile tasking for near-real-time monitoring; interpretable, physics-informed analytics to strengthen ecological inference and decision support; transfer learning and domain-adaptation strategies to improve robustness under distribution shift; standardized, FAIR data practices with open benchmarks and reproducible workflows; and edge-to-cloud processing for timely, operational deployment. By providing a structured, cross-species synthesis—from habitat, migration, and distribution to detection and population estimation in wildlife, and from morphometrics and weight to herd behavior in livestock—this review clarifies how remote sensing and telemetry jointly advance animal ecology and production, and it sets a forward-looking agenda to accelerate robust, ethical, and scalable applications. Our goal is to consolidate current knowledge without overreach, align methods and terminology, and support wider uptake of animal remote sensing and telemetry in biodiversity conservation and sustainable animal production systems.关键词:animal habitat;animal distribution;animal migration;animal detection and population estimation;wild animals;domesticated animals;precision livestock farming571|1192|0更新时间:2025-12-17
摘要:Animal remote sensing and telemetry aim to monitor behavior, movement, and health while minimizing disturbance to individuals and populations. Using satellites, Unmanned Aerial Vehicles (UAVs), radar, acoustic tags, depth cameras, and related modern sensors, these approaches provide multiscale, non-contact observations that support research and management in wildlife conservation, precision livestock farming, and smart fisheries. This review synthesizes recent progress across wild and domesticated animals and clarifies outstanding challenges and opportunities. We first map the field’s development through literature analysis to trace publication trends, leading contributors, and evolving keywords, situating animal remote sensing at the intersection of ecology, geospatial science, animal science, and field-based observation. For wildlife, environment-linked indicators derived from optical and microwave remote sensing (e.g., vegetation indices, sea-surface temperature and height, and ocean color) help explain habitat selection, distribution patterns, and resource suitability, while direct detection with very-high-resolution satellite imagery, aerial photography, and UAV campaigns enables species identification and population estimation over broad extents. Telemetry integrating GPS and inertial sensors, accelerometry, and acoustic systems reveals migration timing, movement ecology, and space-use strategies in birds, terrestrial mammals, and marine species; complementary observations from weather radar networks and passive acoustics capture movements at regional to basin scales. For domesticated animals, non-contact morphometrics, body weight and body-condition scoring, individual identification, and herd distribution and grazing analyses are increasingly achieved with camera and depth sensing. Thermal infrared, millimeter-wave radar, and related biosignal approaches enable contact-free monitoring of temperature, respiration, cardiac activity, and rumination, informing health surveillance and precision management. Across platforms, modern data-processing pipelines—including machine learning for detection, re-identification, and counting—improve accuracy and scalability, while multi-source fusion links animal trajectories with dynamic environmental layers to uncover behavioral drivers and anticipate risk. Despite rapid progress, several challenges persist. There are mismatches between animal movement scales and sensor spatial or temporal resolution; limited sample sizes and label scarcity; dataset bias, domain shift, and fragile model generalization across regions, seasons, backgrounds, and sensor types; occlusion and clutter in complex habitats; and power, weight, and endurance constraints on tags and platforms. Ethical considerations around animal welfare, data governance, and potential disturbance also require explicit assessment. In addition, long-term monitoring demands robust calibration, cross-platform harmonization, and sustainable cost models to ensure continuity and comparability across programs and regions. We also summarize platform-specific error sources and validation practices, including annotation quality, cross-sensor co-registration, geolocation accuracy, and sample representativeness, to guide rigorous study design and reporting. We outline promising directions to address these gaps: miniaturized, energy-efficient tags and lower-cost sensors; higher-revisit imaging constellations and agile tasking for near-real-time monitoring; interpretable, physics-informed analytics to strengthen ecological inference and decision support; transfer learning and domain-adaptation strategies to improve robustness under distribution shift; standardized, FAIR data practices with open benchmarks and reproducible workflows; and edge-to-cloud processing for timely, operational deployment. By providing a structured, cross-species synthesis—from habitat, migration, and distribution to detection and population estimation in wildlife, and from morphometrics and weight to herd behavior in livestock—this review clarifies how remote sensing and telemetry jointly advance animal ecology and production, and it sets a forward-looking agenda to accelerate robust, ethical, and scalable applications. Our goal is to consolidate current knowledge without overreach, align methods and terminology, and support wider uptake of animal remote sensing and telemetry in biodiversity conservation and sustainable animal production systems.关键词:animal habitat;animal distribution;animal migration;animal detection and population estimation;wild animals;domesticated animals;precision livestock farming571|1192|0更新时间:2025-12-17
Research Progress

- “中国林科院资源信息研究所发布亚热带林区多平台激光雷达森林样地点云数据集,为森林生态研究提供重要参考。”
 摘要:Sharing multiplatform laser scanning point clouds of forests is of great significance for laser scanning research and applications in forestry. To this end, the Institute of Forest Resource Information Techniques, Chinese Academy of Forestry has constructed a multiplatform laser scanning point cloud dataset for forest plots in subtropical regions, featuring airborne laser scanning, unmanned-aerial-vehicle laser scanning, and Terrestrial Laser Scanning (TLS) point clouds, along with forest inventory data. Data was collected at Gaofeng Forest Farm in Guangxi, China, covering 25 plots with three tree species: Eucalyptus, Cunninghamia lanceolata, and Pinus massoniana. The field forest inventory data include plot locations, tree positions, diameter at breast height, tree height, height to the first live branch, and crown width. The dataset enables the analysis of forest three-dimensional structural information captured by laser scanners from various platforms, evaluating automated processing algorithms like point cloud registration and tree segmentation. It provides important references for forest research at the regional, plot, and tree levels. Additionally, this study developed a field inventory method guided by TLS data. This method utilizes tree stem point clouds to mark tree positions and measures individual trees according to tree maps, improving operational efficiency.关键词:subtropical forest;laser scanning;airborne;unmanned-aerial-vehicle;terrestrial;multi-platform;forest plot;point cloud;reference dataset;field forest inventory1424|1695|0更新时间:2025-12-17
摘要:Sharing multiplatform laser scanning point clouds of forests is of great significance for laser scanning research and applications in forestry. To this end, the Institute of Forest Resource Information Techniques, Chinese Academy of Forestry has constructed a multiplatform laser scanning point cloud dataset for forest plots in subtropical regions, featuring airborne laser scanning, unmanned-aerial-vehicle laser scanning, and Terrestrial Laser Scanning (TLS) point clouds, along with forest inventory data. Data was collected at Gaofeng Forest Farm in Guangxi, China, covering 25 plots with three tree species: Eucalyptus, Cunninghamia lanceolata, and Pinus massoniana. The field forest inventory data include plot locations, tree positions, diameter at breast height, tree height, height to the first live branch, and crown width. The dataset enables the analysis of forest three-dimensional structural information captured by laser scanners from various platforms, evaluating automated processing algorithms like point cloud registration and tree segmentation. It provides important references for forest research at the regional, plot, and tree levels. Additionally, this study developed a field inventory method guided by TLS data. This method utilizes tree stem point clouds to mark tree positions and measures individual trees according to tree maps, improving operational efficiency.关键词:subtropical forest;laser scanning;airborne;unmanned-aerial-vehicle;terrestrial;multi-platform;forest plot;point cloud;reference dataset;field forest inventory1424|1695|0更新时间:2025-12-17 - “在森林资源监测领域,专家通过结合高光谱和LiDAR数据,设计了4种分类策略,显著提升了人工林树种分类精度,为森林资源高效监测和管理提供了科学基础。”
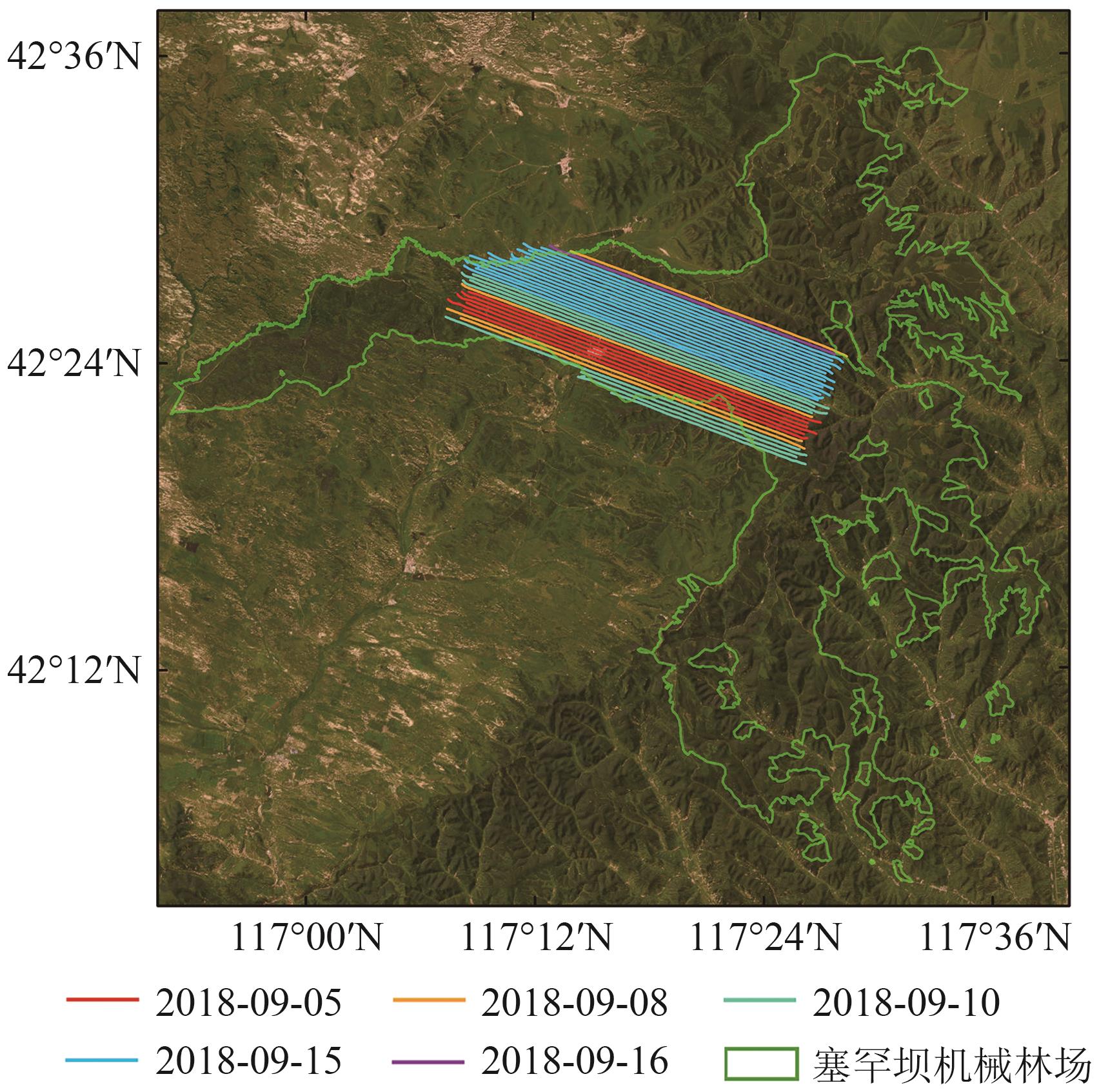 摘要:This research aims to examine the key factors influencing the accuracy of tree species classification using airborne hyperspectral data combined with Light Detection And Ranging (LiDAR) data in forest environments. Accurate identification of individual tree species is essential for effective forest resource monitoring, management, ecosystem assessment, and biodiversity conservation. While many small-scale studies have explored tree species classification in forests with diverse species compositions and complex age structures, achieving this over larger areas remains a significant challenge. This study focuses on evaluating the effects of spectral consistency correction, canopy height information, and individual tree canopy segmentation on classification accuracy. Saihanba Mechanical Forest Farm, a large-scale artificial plantation, was selected as the study site to explore these factors.To assess the effect of different factors on tree species classification accuracy, this research utilized a random forest classification algorithm and developed four distinct classification strategies. The first strategy used vegetation indices derived from multiflightline images without applying Bidirectional Reflectance Distribution Function (BRDF) correction. The second strategy incorporated BRDF correction into the multiflightline images before deriving vegetation indices. The third strategy integrated canopy height information, specifically the Canopy Height Model (CHM), with the BRDF-corrected vegetation indices. The fourth and final strategy combined BRDF-corrected vegetation indices, CHM, and individual tree canopy segmentation data. The classification accuracy of each strategy was systematically compared to quantify the contribution of each factor toward improving tree species classification precision.Results indicated that individual tree canopy segmentation significantly reduced misclassification errors arising from the mixing of multiple species within a single canopy, leading to a notable 10.74% improvement in classification accuracy. Using the random forest model’s feature importance ranking, individual tree segmentation emerged as the most critical factor, followed by BRDF correction, then CHM. Although BRDF correction reduced spectral reflectance variability caused by differing Sun observation geometries across flight strips, it only led to a modest improvement in classification accuracy of 3.48%. The introduction of CHM yielded minimal gains in accuracy, contributing just 0.67%, particularly in areas with uniform vertical forest structures or species spanning multiple age cohorts.This study demonstrates that integrating airborne hyperspectral data with LiDAR data holds substantial promise for enhancing tree species classification in large-scale artificial plantations. Among the factors analyzed, individual tree segmentation proved to be the most impactful in improving accuracy. By contrast, the relatively minor influence of BRDF correction and canopy height features underscores the need for further refinement and optimization. Overall, the findings emphasize the importance of considering multiple factors in remote sensing workflows to enhance the efficiency and accuracy of forest resource monitoring, management, and other forestry-related applications, especially in expansive forest environments. These insights provide a valuable theoretical foundation and practical recommendations for future forest management and ecological monitoring efforts.关键词:Tree Species Classification;airborne hyperspectral data;BRDF correction;LIDAR data;individual tree segmentation;Random Forest;vegetation indices;Saihanba mechanized forest farm1166|961|0更新时间:2025-12-17
摘要:This research aims to examine the key factors influencing the accuracy of tree species classification using airborne hyperspectral data combined with Light Detection And Ranging (LiDAR) data in forest environments. Accurate identification of individual tree species is essential for effective forest resource monitoring, management, ecosystem assessment, and biodiversity conservation. While many small-scale studies have explored tree species classification in forests with diverse species compositions and complex age structures, achieving this over larger areas remains a significant challenge. This study focuses on evaluating the effects of spectral consistency correction, canopy height information, and individual tree canopy segmentation on classification accuracy. Saihanba Mechanical Forest Farm, a large-scale artificial plantation, was selected as the study site to explore these factors.To assess the effect of different factors on tree species classification accuracy, this research utilized a random forest classification algorithm and developed four distinct classification strategies. The first strategy used vegetation indices derived from multiflightline images without applying Bidirectional Reflectance Distribution Function (BRDF) correction. The second strategy incorporated BRDF correction into the multiflightline images before deriving vegetation indices. The third strategy integrated canopy height information, specifically the Canopy Height Model (CHM), with the BRDF-corrected vegetation indices. The fourth and final strategy combined BRDF-corrected vegetation indices, CHM, and individual tree canopy segmentation data. The classification accuracy of each strategy was systematically compared to quantify the contribution of each factor toward improving tree species classification precision.Results indicated that individual tree canopy segmentation significantly reduced misclassification errors arising from the mixing of multiple species within a single canopy, leading to a notable 10.74% improvement in classification accuracy. Using the random forest model’s feature importance ranking, individual tree segmentation emerged as the most critical factor, followed by BRDF correction, then CHM. Although BRDF correction reduced spectral reflectance variability caused by differing Sun observation geometries across flight strips, it only led to a modest improvement in classification accuracy of 3.48%. The introduction of CHM yielded minimal gains in accuracy, contributing just 0.67%, particularly in areas with uniform vertical forest structures or species spanning multiple age cohorts.This study demonstrates that integrating airborne hyperspectral data with LiDAR data holds substantial promise for enhancing tree species classification in large-scale artificial plantations. Among the factors analyzed, individual tree segmentation proved to be the most impactful in improving accuracy. By contrast, the relatively minor influence of BRDF correction and canopy height features underscores the need for further refinement and optimization. Overall, the findings emphasize the importance of considering multiple factors in remote sensing workflows to enhance the efficiency and accuracy of forest resource monitoring, management, and other forestry-related applications, especially in expansive forest environments. These insights provide a valuable theoretical foundation and practical recommendations for future forest management and ecological monitoring efforts.关键词:Tree Species Classification;airborne hyperspectral data;BRDF correction;LIDAR data;individual tree segmentation;Random Forest;vegetation indices;Saihanba mechanized forest farm1166|961|0更新时间:2025-12-17 - “在森林生物量估算领域,研究者利用激光雷达生物量指数LBI计算落叶松生物量,验证了其高精度估算能力,并在不同区域展示出良好的通用性。”
 摘要:The LiDAR Biomass Index (LBI) can calculate the aboveground biomass (AGB) of individual trees on the basis of airborne LiDAR data, and it has been verified to have high accuracy for biomass calculation at tree and plot levels. However, its ability to complete large-scale forest biomass mapping has not been fully explored. The aim of this research is to verify the accuracy of LBI for AGB estimation on a subcompartment scale, taking the widely planted Larix olgensis tree species in north China as an example and laying a theoretical foundation for the widespread application of this index.First, the existing tree species classification results based on hyperspectral data were used to select the point clouds of L. olgensis species in Mengjiagang Forest Farm. Second, the NSC algorithm was employed to complete the individual tree segmentation of the selected point clouds. Third, the LBI was used to calculate the forest biomass of each individual tree. Finally, with reference to the AGB_LBI biomass model of L. olgensis species constructed on the basis of 35 individual sample trees, the biomass of each individual tree was calculated, and the biomass of each subcompartment was obtained through accumulating the biomass of individual trees within the subcompartment. In this research, the calculation accuracy was verified through the silviculture survey data obtained from the local forestry department, including over 70000 individual trees. Meanwhile, the universality of LBI in estimating the biomass of the same tree species across different regions at the subcompartment level was evaluated on the basis of the existing AGB_LBI models of other forest farms, and the results were compared with those of the commonly used LiDAR Metric-based Regression (LMR) methods.The results indicated that LBI can achieve forest biomass estimation at the subcompartment level with high accuracy. When individual tree samples selected from different regions were used to calibrate the AGB_ LBI model, the obtained biomass values were comparable with the measured data, with R2 ranging from 0.86 to 0.87 and relative root-mean-square error (RMSE) ranging from 34.20% to 40.23%. The biomass results calculated from each model did not have significant differences. However, the increase in the number of sample trees used for model calibration still exerted a certain effect on the robustness and accuracy of biomass calculation. Overall, the accuracy of the LBI-based method was comparable to that of the LMR method, although the sample trees used to calibrate the AGB_LBI model only accounted for 1% of that used to calibrate the LMR model. Meanwhile, the LBI method exhibited stronger universality among the same tree species in different forest farms. The AGB_LBI model was used to calculate the biomass of each individual tree in the western region of Mengjiagang Forest Farm and complete the biomass mapping. The obtained biomass distribution presented a similar trend to the existing biomass map and was consistent with the forest subcompartment map, achieving high consistency at the scale of 20 m×20 m (R2=0.75, RMSE=1.55 t).The high-precision estimation of biomass by LBI at the subcompartment scale demonstrates its potential for conducting large-scale estimation of forest AGB. Because of the difficulty in obtaining validation data, this research only verified its accuracy on the species of L. olgensis and did not conduct experiments on other tree species. Nevertheless, previous studies have shown that this method can theoretically be applied to other tree species and forest situations, which is worth further exploration. This research provides a theoretical basis for precise, large-scale, and high-precision forest biomass estimation.关键词:LiDAR Biomass Index;LBI;airborne LiDAR;individual tree;sub-compartment level;biomass966|918|0更新时间:2025-12-17
摘要:The LiDAR Biomass Index (LBI) can calculate the aboveground biomass (AGB) of individual trees on the basis of airborne LiDAR data, and it has been verified to have high accuracy for biomass calculation at tree and plot levels. However, its ability to complete large-scale forest biomass mapping has not been fully explored. The aim of this research is to verify the accuracy of LBI for AGB estimation on a subcompartment scale, taking the widely planted Larix olgensis tree species in north China as an example and laying a theoretical foundation for the widespread application of this index.First, the existing tree species classification results based on hyperspectral data were used to select the point clouds of L. olgensis species in Mengjiagang Forest Farm. Second, the NSC algorithm was employed to complete the individual tree segmentation of the selected point clouds. Third, the LBI was used to calculate the forest biomass of each individual tree. Finally, with reference to the AGB_LBI biomass model of L. olgensis species constructed on the basis of 35 individual sample trees, the biomass of each individual tree was calculated, and the biomass of each subcompartment was obtained through accumulating the biomass of individual trees within the subcompartment. In this research, the calculation accuracy was verified through the silviculture survey data obtained from the local forestry department, including over 70000 individual trees. Meanwhile, the universality of LBI in estimating the biomass of the same tree species across different regions at the subcompartment level was evaluated on the basis of the existing AGB_LBI models of other forest farms, and the results were compared with those of the commonly used LiDAR Metric-based Regression (LMR) methods.The results indicated that LBI can achieve forest biomass estimation at the subcompartment level with high accuracy. When individual tree samples selected from different regions were used to calibrate the AGB_ LBI model, the obtained biomass values were comparable with the measured data, with R2 ranging from 0.86 to 0.87 and relative root-mean-square error (RMSE) ranging from 34.20% to 40.23%. The biomass results calculated from each model did not have significant differences. However, the increase in the number of sample trees used for model calibration still exerted a certain effect on the robustness and accuracy of biomass calculation. Overall, the accuracy of the LBI-based method was comparable to that of the LMR method, although the sample trees used to calibrate the AGB_LBI model only accounted for 1% of that used to calibrate the LMR model. Meanwhile, the LBI method exhibited stronger universality among the same tree species in different forest farms. The AGB_LBI model was used to calculate the biomass of each individual tree in the western region of Mengjiagang Forest Farm and complete the biomass mapping. The obtained biomass distribution presented a similar trend to the existing biomass map and was consistent with the forest subcompartment map, achieving high consistency at the scale of 20 m×20 m (R2=0.75, RMSE=1.55 t).The high-precision estimation of biomass by LBI at the subcompartment scale demonstrates its potential for conducting large-scale estimation of forest AGB. Because of the difficulty in obtaining validation data, this research only verified its accuracy on the species of L. olgensis and did not conduct experiments on other tree species. Nevertheless, previous studies have shown that this method can theoretically be applied to other tree species and forest situations, which is worth further exploration. This research provides a theoretical basis for precise, large-scale, and high-precision forest biomass estimation.关键词:LiDAR Biomass Index;LBI;airborne LiDAR;individual tree;sub-compartment level;biomass966|918|0更新时间:2025-12-17 - “在山地林区地表及冠层表面检测领域,专家提出了基于方向自适应的点排序识别聚类结构DA-OPTICS方法,实现了高精度检测,为森林空间结构参数反演提供可靠数据基础。”
 摘要:The successful launch of the Ice, Cloud, and land Elevation Satellite-2 (ICESat-2), carrying the Advanced Topographic Laser Altimeter System (ATLAS), has made it possible to accurately quantify global vegetation structure. However, given the limitations of the sensitive photon detection system, its data contain a large amount of background noise photons. Aiming at the problem that ICESat-2/ATLAS has low signal extraction accuracy in mountainous forest areas, which leads to the difficulty of ground and canopy surface detection, the method of ground and canopy surface detection based on direction-adaptive ordering points to identify the clustering structure (DA-OPTICS) is proposed.First, the initial ground surface is obtained through segmented curve fitting based on random sample consensus (RANSAC), which is used to construct a direction-adaptive elliptical searching area to replace the traditional circle in OPTICS, forming the DA-OPTICS. On the basis of this algorithm, the reachability distance of all photon point clouds is obtained. Potential ground signals and surface are obtained successively via a “two-step method”: Otsu’s method is first introduced to obtain potential ground signals, and potential ground surface is then acquired by fitting potential ground signals through RANSAC. The “two-step method” is iterated several times until the similarity between the potential ground surface obtained before and after is greater than 90%, indicating that the potential ground surface is considered a fine ground surface. Second, the effect of terrain on photons is eliminated by referring to the fine ground surface, and the vegetation signal is extracted by vertical elliptical OPTICS. Finally, on the basis of the vegetation signal, the canopy surface is detected by combining the elevation percentile and piecewise cubic Hermite interpolation curve fitting.The ICESat-2 ATL03 data of Mengjiagang Forest Farm in Heilongjiang Province and Fushun Forest Farm in Liaoning Province are used as research objects to carry out experiments, and the accuracy is verified by manually labeled samples and unmanned aerial vehicle products. Results show that the extraction accuracy (F) of ground surface and vegetation signals in the mountainous forest areas is 0.97, which is about 0.07 higher than that of the OPTICS based on elliptical searching area. In addition, the RMSEs of ground and canopy surfaces detected by the proposed method are 1.08 m and 2.33 m, respectively, compared with 1.92 m and 3.29 m of ATL08, respectively, implying a significant improvement in accuracy.Therefore, compared with the OPTICS based on elliptical searching area and ATL08, DA-OPTICS has higher precision in extracting vegetation signal photons and detecting ground and canopy surfaces. It is more suitable for areas with large gradient changes such as mountainous forest areas and can provide a reliable data foundation for the subsequent inversion of forest spatial structure.关键词:ICESat-2/ATLAS;direction adaptive;DA-OPTICS;iterative refinement;terrain slope;mountain forest area154|433|0更新时间:2025-12-17
摘要:The successful launch of the Ice, Cloud, and land Elevation Satellite-2 (ICESat-2), carrying the Advanced Topographic Laser Altimeter System (ATLAS), has made it possible to accurately quantify global vegetation structure. However, given the limitations of the sensitive photon detection system, its data contain a large amount of background noise photons. Aiming at the problem that ICESat-2/ATLAS has low signal extraction accuracy in mountainous forest areas, which leads to the difficulty of ground and canopy surface detection, the method of ground and canopy surface detection based on direction-adaptive ordering points to identify the clustering structure (DA-OPTICS) is proposed.First, the initial ground surface is obtained through segmented curve fitting based on random sample consensus (RANSAC), which is used to construct a direction-adaptive elliptical searching area to replace the traditional circle in OPTICS, forming the DA-OPTICS. On the basis of this algorithm, the reachability distance of all photon point clouds is obtained. Potential ground signals and surface are obtained successively via a “two-step method”: Otsu’s method is first introduced to obtain potential ground signals, and potential ground surface is then acquired by fitting potential ground signals through RANSAC. The “two-step method” is iterated several times until the similarity between the potential ground surface obtained before and after is greater than 90%, indicating that the potential ground surface is considered a fine ground surface. Second, the effect of terrain on photons is eliminated by referring to the fine ground surface, and the vegetation signal is extracted by vertical elliptical OPTICS. Finally, on the basis of the vegetation signal, the canopy surface is detected by combining the elevation percentile and piecewise cubic Hermite interpolation curve fitting.The ICESat-2 ATL03 data of Mengjiagang Forest Farm in Heilongjiang Province and Fushun Forest Farm in Liaoning Province are used as research objects to carry out experiments, and the accuracy is verified by manually labeled samples and unmanned aerial vehicle products. Results show that the extraction accuracy (F) of ground surface and vegetation signals in the mountainous forest areas is 0.97, which is about 0.07 higher than that of the OPTICS based on elliptical searching area. In addition, the RMSEs of ground and canopy surfaces detected by the proposed method are 1.08 m and 2.33 m, respectively, compared with 1.92 m and 3.29 m of ATL08, respectively, implying a significant improvement in accuracy.Therefore, compared with the OPTICS based on elliptical searching area and ATL08, DA-OPTICS has higher precision in extracting vegetation signal photons and detecting ground and canopy surfaces. It is more suitable for areas with large gradient changes such as mountainous forest areas and can provide a reliable data foundation for the subsequent inversion of forest spatial structure.关键词:ICESat-2/ATLAS;direction adaptive;DA-OPTICS;iterative refinement;terrain slope;mountain forest area154|433|0更新时间:2025-12-17 - “据最新报道,中国首颗陆地生态系统碳监测卫星TECIS全波形激光雷达数据在森林冠层高度制图及生物量估算中具有重要应用价值。”
 摘要:The Terrestrial Ecosystem Carbon Inventory Satellite (TECIS) is China’s first remote sensing satellite with space-borne LiDAR as the main payload, which aims at quantitatively monitoring terrestrial ecosystem carbon storage, forest resources, and forest productivity; serving the goals of “carbon peaking and carbon neutrality”; and monitoring and evaluating major projects for the protection and restoration of important ecosystems in China. In this study, the Relative Height metrics RHn (where n ranges from 0 to 100) , which is calculated by the full-waveform energy distribution, was used to evaluate the ability of characterizing forest canopy height for the full-waveform data of the full-waveform LiDAR onboard TECIS. The ability in canopy height estimation between fixed and variable gain waveform data was compared. Moreover, the influence of slope on canopy height extraction was analyzed. Six tracks of L2 products from TECIS full-waveform LiDAR passing the test area of a temperate coniferous-broadleaved mixed forest in Quebec, Canada were selected for analysis. Results show that the select of starting RH metrics for estimating forest canopy height significantly affects the accuracy of the results. Specifically, employing a lower RH metric tends to overestimate canopy height, whereas a higher RH metric results in an underestimation. In addition, the background noise threshold also has a certain influence on the accuracy of canopy height estimation. The Root Mean Square Error (RMSE) for forest canopy height can reach up to 3.58 meters, whereas the Median Error (ME) improves to less than 1.0 meter, and the Mean Absolute Error (MAE) is recorded at 2.48 meters after removing several anomalous laser points. Furthermore, in comparison to the final peak position derived from waveform decomposition, the RH5 metric demonstrates its superiority as a baseline for estimating canopy height, exhibiting reduced sensitivity in inversion accuracy to variations in terrain slope. The accuracy of canopy height retrieval using variable and fixed gain waveform data is comparable. The configuration of variable and fixed gains is beneficial for enhancing data effectiveness in forest areas. The conclusions drawn from this analysis will significantly aid in the application of the laser altimetry data from TECIS for canopy height mapping and biomass estimation in forests.关键词:Terrestrial Ecosystem Carbon Inventory Satellite;full-waveform LiDAR;forest canopy height;Relative Height Metrics;Background noise threshold;terrain slope996|931|0更新时间:2025-12-17
摘要:The Terrestrial Ecosystem Carbon Inventory Satellite (TECIS) is China’s first remote sensing satellite with space-borne LiDAR as the main payload, which aims at quantitatively monitoring terrestrial ecosystem carbon storage, forest resources, and forest productivity; serving the goals of “carbon peaking and carbon neutrality”; and monitoring and evaluating major projects for the protection and restoration of important ecosystems in China. In this study, the Relative Height metrics RHn (where n ranges from 0 to 100) , which is calculated by the full-waveform energy distribution, was used to evaluate the ability of characterizing forest canopy height for the full-waveform data of the full-waveform LiDAR onboard TECIS. The ability in canopy height estimation between fixed and variable gain waveform data was compared. Moreover, the influence of slope on canopy height extraction was analyzed. Six tracks of L2 products from TECIS full-waveform LiDAR passing the test area of a temperate coniferous-broadleaved mixed forest in Quebec, Canada were selected for analysis. Results show that the select of starting RH metrics for estimating forest canopy height significantly affects the accuracy of the results. Specifically, employing a lower RH metric tends to overestimate canopy height, whereas a higher RH metric results in an underestimation. In addition, the background noise threshold also has a certain influence on the accuracy of canopy height estimation. The Root Mean Square Error (RMSE) for forest canopy height can reach up to 3.58 meters, whereas the Median Error (ME) improves to less than 1.0 meter, and the Mean Absolute Error (MAE) is recorded at 2.48 meters after removing several anomalous laser points. Furthermore, in comparison to the final peak position derived from waveform decomposition, the RH5 metric demonstrates its superiority as a baseline for estimating canopy height, exhibiting reduced sensitivity in inversion accuracy to variations in terrain slope. The accuracy of canopy height retrieval using variable and fixed gain waveform data is comparable. The configuration of variable and fixed gains is beneficial for enhancing data effectiveness in forest areas. The conclusions drawn from this analysis will significantly aid in the application of the laser altimetry data from TECIS for canopy height mapping and biomass estimation in forests.关键词:Terrestrial Ecosystem Carbon Inventory Satellite;full-waveform LiDAR;forest canopy height;Relative Height Metrics;Background noise threshold;terrain slope996|931|0更新时间:2025-12-17 - “在森林蓄积量估测领域,瑞士专家评估了ICESat-2数据中森林三维结构特征的作用,建立了最优模型,有效提升了复杂林分条件下的估测精度。”
 摘要:Satellite-based photon-counting LiDAR systems, represented by the Advanced Topographic Laser Altimeter System (ATLAS) onboard the Ice, Cloud, and land Elevation Satellite-2 (ICESat-2), enable rapid acquisition of large-scale three-dimensional vegetation information and have been widely applied to forest parameter retrieval. However, their general applicability remains limited. To address this issue, this study focused on mixed coniferous and broadleaved forests in the canton of Aargau, Switzerland, and evaluated the role of canopy horizontal and vertical structural features in improving the accuracy of stand volume estimation from ICESat-2 data under complex forest conditions. Furthermore, we explored the optimal model form for this region and compared it against a baseline model using only conventional height-based statistical metrics. First, the denoised ICESat-2 ATLAS data were segmented into 100 m estimation units, and quality control was performed to identify and remove anomalous units, ensuring stable data quality. Next, feature grouping pre-screening combined with rule-constrained all-subset selection was applied to integrate point cloud height distribution metrics, canopy height and heterogeneity indices, and vertical structural features for stand volume estimation, yielding the optimal feature subset. Results indicated that the best-performing model for stand volume estimation in the Aargau mixed forests comprised the mean top-of-canopy height, the 65% height percentile, the leaf area–weighted canopy volume, and the mean value of the foliage profile. Ten-fold cross-validation demonstrated that this model achieved high accuracy, with an average R²=0.78, RMSE=92.48 m3/hm2, and rRMSE=0.24. By comparison, the baseline model using only traditional metrics yielded an R²=0.66 and an rRMSE reduced from 0.28 to 0.24, confirming that the incorporation of structural features substantially improved the accuracy of ICESat-2-based stand volume estimation, particularly in forests with high canopy heterogeneity. In conclusion, integrating three-dimensional structural attributes significantly enhances the applicability of ICESat-2 data for forest stand volume estimation under complex stand conditions, thereby providing methodological support for large-scale forest volume and carbon stock monitoring.关键词:Forest Stock Volume;ICESat-2 ATLAS;forest structural features;canopy height heterogeneity;vertical structure;quality control;preliminary grouping feature selection;rule-constrained all subset135|130|0更新时间:2025-12-17
摘要:Satellite-based photon-counting LiDAR systems, represented by the Advanced Topographic Laser Altimeter System (ATLAS) onboard the Ice, Cloud, and land Elevation Satellite-2 (ICESat-2), enable rapid acquisition of large-scale three-dimensional vegetation information and have been widely applied to forest parameter retrieval. However, their general applicability remains limited. To address this issue, this study focused on mixed coniferous and broadleaved forests in the canton of Aargau, Switzerland, and evaluated the role of canopy horizontal and vertical structural features in improving the accuracy of stand volume estimation from ICESat-2 data under complex forest conditions. Furthermore, we explored the optimal model form for this region and compared it against a baseline model using only conventional height-based statistical metrics. First, the denoised ICESat-2 ATLAS data were segmented into 100 m estimation units, and quality control was performed to identify and remove anomalous units, ensuring stable data quality. Next, feature grouping pre-screening combined with rule-constrained all-subset selection was applied to integrate point cloud height distribution metrics, canopy height and heterogeneity indices, and vertical structural features for stand volume estimation, yielding the optimal feature subset. Results indicated that the best-performing model for stand volume estimation in the Aargau mixed forests comprised the mean top-of-canopy height, the 65% height percentile, the leaf area–weighted canopy volume, and the mean value of the foliage profile. Ten-fold cross-validation demonstrated that this model achieved high accuracy, with an average R²=0.78, RMSE=92.48 m3/hm2, and rRMSE=0.24. By comparison, the baseline model using only traditional metrics yielded an R²=0.66 and an rRMSE reduced from 0.28 to 0.24, confirming that the incorporation of structural features substantially improved the accuracy of ICESat-2-based stand volume estimation, particularly in forests with high canopy heterogeneity. In conclusion, integrating three-dimensional structural attributes significantly enhances the applicability of ICESat-2 data for forest stand volume estimation under complex stand conditions, thereby providing methodological support for large-scale forest volume and carbon stock monitoring.关键词:Forest Stock Volume;ICESat-2 ATLAS;forest structural features;canopy height heterogeneity;vertical structure;quality control;preliminary grouping feature selection;rule-constrained all subset135|130|0更新时间:2025-12-17
ForestResourcesDynamicMonitoringandForestVolumeEstimationUsingLiDARRemoteSensingTechnologies
- “遥感技术在林业调查中取得新进展,专家构建了融合主被动遥感数据的森林分类深度学习网络,总体分类精度达到95.24%。”
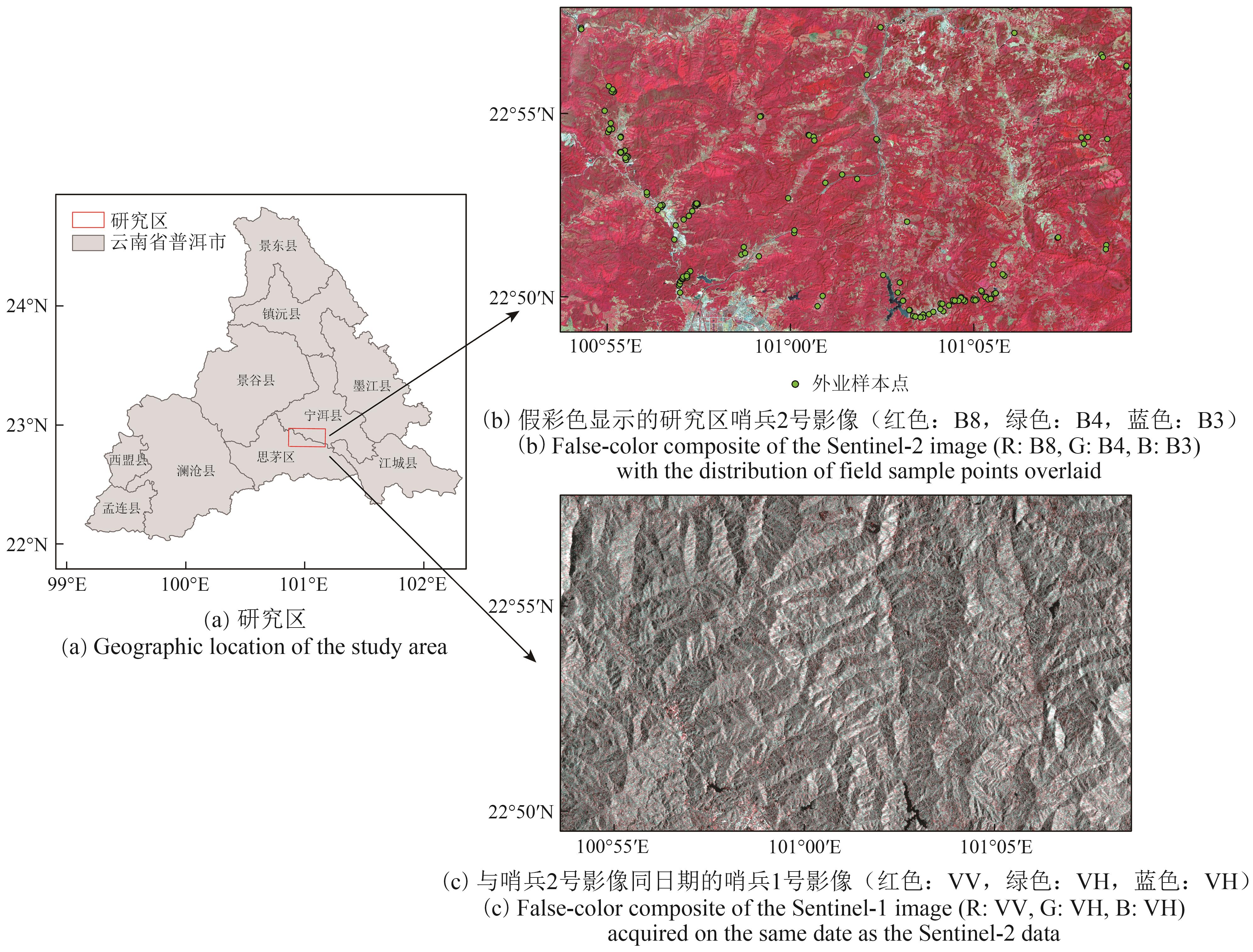 摘要:Remote sensing, with its broad coverage, high timeliness, and ability to acquire multidimensional information, has become a vital tool for forestry surveys. Multispectral remote sensing imagery offers high spatial and spectral resolution, effectively capturing the spectral differences between various ground features. In parallel, Synthetic Aperture Radar (SAR) data provide stable surface structural information and textural features, serving as a crucial complement to spectral data. However, inherent discrepancies in modal structure and information representation between active (SAR) and passive (multispectral) remote sensing data often limit fusion effectiveness, which can ultimately influence classification accuracy. To address this challenge, our study focuses on a specific region in Pu’er City, Yunnan Province. We selected three key forest tree species groups—Pinus kesiya, Eucalyptus, and Quercus spp.—along with one type of economic forest, tea plantation, and three other ground object types as classification targets. Under small-sample conditions, we developed a deep learning network for forest classification that fuses active and passive remote sensing data. Our method, which integrates Sentinel-2 multispectral imagery with Sentinel-1 SAR imagery, proposes a multispectrum-dominated cross-attention fusion network. A key feature is the introduction of a regularized gating mechanism with a learnable dropout ratio, enabling dynamic regulation of self-attention and cross-attention feature fusion. Within this fusion process, the model uses a self-attention mechanism to extract prominent features from multispectral data. Meanwhile, cross-attention guides its response to critical regions in SAR data, dynamically controlling each modality’s information contribution at the feature fusion stage. Our experimental results demonstrate that the proposed method achieves optimal performance when compared with diverse fusion strategies across various fusion levels. It yielded an overall classification accuracy of 95.24%. Specifically, the classification precision for Eucalyptus, tea plantation, Quercus spp., and P. kesiya were 96.78%, 94.07%, 91.73%, and 92.90%, respectively. This study successfully validates the effectiveness of the cross-attention mechanism in collaboratively modeling active and passive remote sensing information, offering a viable approach and technical support for multisource remote sensing-based forest classification in complex environments.关键词:Sentinel-2;Sentinel-1;Cross-Attention;Feature fusion;Forest Classification;Prototypical Network;concrete dropout281|636|0更新时间:2025-12-17
摘要:Remote sensing, with its broad coverage, high timeliness, and ability to acquire multidimensional information, has become a vital tool for forestry surveys. Multispectral remote sensing imagery offers high spatial and spectral resolution, effectively capturing the spectral differences between various ground features. In parallel, Synthetic Aperture Radar (SAR) data provide stable surface structural information and textural features, serving as a crucial complement to spectral data. However, inherent discrepancies in modal structure and information representation between active (SAR) and passive (multispectral) remote sensing data often limit fusion effectiveness, which can ultimately influence classification accuracy. To address this challenge, our study focuses on a specific region in Pu’er City, Yunnan Province. We selected three key forest tree species groups—Pinus kesiya, Eucalyptus, and Quercus spp.—along with one type of economic forest, tea plantation, and three other ground object types as classification targets. Under small-sample conditions, we developed a deep learning network for forest classification that fuses active and passive remote sensing data. Our method, which integrates Sentinel-2 multispectral imagery with Sentinel-1 SAR imagery, proposes a multispectrum-dominated cross-attention fusion network. A key feature is the introduction of a regularized gating mechanism with a learnable dropout ratio, enabling dynamic regulation of self-attention and cross-attention feature fusion. Within this fusion process, the model uses a self-attention mechanism to extract prominent features from multispectral data. Meanwhile, cross-attention guides its response to critical regions in SAR data, dynamically controlling each modality’s information contribution at the feature fusion stage. Our experimental results demonstrate that the proposed method achieves optimal performance when compared with diverse fusion strategies across various fusion levels. It yielded an overall classification accuracy of 95.24%. Specifically, the classification precision for Eucalyptus, tea plantation, Quercus spp., and P. kesiya were 96.78%, 94.07%, 91.73%, and 92.90%, respectively. This study successfully validates the effectiveness of the cross-attention mechanism in collaboratively modeling active and passive remote sensing information, offering a viable approach and technical support for multisource remote sensing-based forest classification in complex environments.关键词:Sentinel-2;Sentinel-1;Cross-Attention;Feature fusion;Forest Classification;Prototypical Network;concrete dropout281|636|0更新时间:2025-12-17 - “在目标检测领域,研究者提出了一种红外与可见光特征自适应融合的多模态目标检测方法,有效提高了复杂环境下的检测精度。”
 摘要:Target detection methods are mainly based on visible light images. Although they can fully display the details and texture features of the target, when the target is blurred or blocked, or the light is excessively strong or dark, the target information is difficult to fully obtain by relying solely on visible light sensors, thus affecting the target detection effect. By contrast, infrared sensors have the advantages of strong resistance to environmental interference, insensitivity to light, and ability to reflect target temperature, which can compensate for the shortcomings of visible light imaging. Therefore, infrared features are integrated into target detection based on visible light.This study proposes a multimodal target detection method that adaptively fuses infrared and visible light features. This method uses the YOLOv8 target detection framework as the basic network to extract multiscale feature information. On this basis, a new multimodal hybrid attention module (cross-modal hybrid attention module) is constructed. This module extracts the complementary features of visible light and infrared images and jointly performs channel and spatial attention analyses to achieve the communication and reorganization of cross-modal information weights, thereby improving the perception of complementary features between different modalities. In addition, a visible light-infrared feature adaptive fusion module with ambient light intensity as an indicator is constructed. An illumination awareness module is first designed to evaluate the feature richness of the target contained in the visible light image in accordance with the light intensity of the image. It is then incorporated into a cross-modal adaptive fusion module to guide the adaptive fusion process, solving the problem that conventional fusion methods hardly achieve dynamic processing based on multimodal data features. Thus, target detection based on multimodal feature fusion is realized.Several classic target detection models and current advanced detection methods are used to conduct comparative experiments with the MAF-YOLO model proposed in this paper to fully demonstrate its effectiveness. The classic target detection models include Faster R-CNN and YOLOv8. Because they are both target detection models for single-modality images, this study conducts experiments on visible light and infrared modalities. Current advanced models include CFT, which is the first application of Transformer to the field of multispectral target detection; TarDAL, which uses generative adversarial networks to generate fused images; and SuperYOLO, which achieves super-resolution reconstruction based on YOLOv5 and improves the accuracy of multimodal target detection. Comparative experiments are conducted on the M3FD street view dataset and the DroneVehicle aerial vehicle dataset to test the robustness of these methods in different lighting environments and scenes. Experimental results show that the proposed method achieves higher detection accuracy compared with current state-of-the-art single-modal and multimodal object detection methods in both datasets.On the basis of the YOLOv8 model, this study proposes a target detection network based on visible light–infrared multimodal feature fusion (MAF-YOLO). A new cross-modal hybrid attention mechanism is designed to fully utilize the complementary features of visible light and infrared information. Moreover, an illumination perception module and an adaptive fusion module are constructed to perform midterm fusion of dual-stream information, extracting the complementary features of the two modalities for target detection. Comparative experiments of the proposed method with various existing target detection models on the DroneVehicle and M3FD datasets show that MAF-YOLO can achieve good detection performance and robustness in complex environments. Experimental findings prove that the proposed method can effectively solve the problem of insufficient visible light modal target features in complex environments and realize accurate target detection with the fusion of infrared and visible light multimodal features.关键词:target detection;multimodal;convolutional neural network;Feature fusion;attention mechanism;visible light imaging;infrared imaging;deep learning573|2228|0更新时间:2025-12-17
摘要:Target detection methods are mainly based on visible light images. Although they can fully display the details and texture features of the target, when the target is blurred or blocked, or the light is excessively strong or dark, the target information is difficult to fully obtain by relying solely on visible light sensors, thus affecting the target detection effect. By contrast, infrared sensors have the advantages of strong resistance to environmental interference, insensitivity to light, and ability to reflect target temperature, which can compensate for the shortcomings of visible light imaging. Therefore, infrared features are integrated into target detection based on visible light.This study proposes a multimodal target detection method that adaptively fuses infrared and visible light features. This method uses the YOLOv8 target detection framework as the basic network to extract multiscale feature information. On this basis, a new multimodal hybrid attention module (cross-modal hybrid attention module) is constructed. This module extracts the complementary features of visible light and infrared images and jointly performs channel and spatial attention analyses to achieve the communication and reorganization of cross-modal information weights, thereby improving the perception of complementary features between different modalities. In addition, a visible light-infrared feature adaptive fusion module with ambient light intensity as an indicator is constructed. An illumination awareness module is first designed to evaluate the feature richness of the target contained in the visible light image in accordance with the light intensity of the image. It is then incorporated into a cross-modal adaptive fusion module to guide the adaptive fusion process, solving the problem that conventional fusion methods hardly achieve dynamic processing based on multimodal data features. Thus, target detection based on multimodal feature fusion is realized.Several classic target detection models and current advanced detection methods are used to conduct comparative experiments with the MAF-YOLO model proposed in this paper to fully demonstrate its effectiveness. The classic target detection models include Faster R-CNN and YOLOv8. Because they are both target detection models for single-modality images, this study conducts experiments on visible light and infrared modalities. Current advanced models include CFT, which is the first application of Transformer to the field of multispectral target detection; TarDAL, which uses generative adversarial networks to generate fused images; and SuperYOLO, which achieves super-resolution reconstruction based on YOLOv5 and improves the accuracy of multimodal target detection. Comparative experiments are conducted on the M3FD street view dataset and the DroneVehicle aerial vehicle dataset to test the robustness of these methods in different lighting environments and scenes. Experimental results show that the proposed method achieves higher detection accuracy compared with current state-of-the-art single-modal and multimodal object detection methods in both datasets.On the basis of the YOLOv8 model, this study proposes a target detection network based on visible light–infrared multimodal feature fusion (MAF-YOLO). A new cross-modal hybrid attention mechanism is designed to fully utilize the complementary features of visible light and infrared information. Moreover, an illumination perception module and an adaptive fusion module are constructed to perform midterm fusion of dual-stream information, extracting the complementary features of the two modalities for target detection. Comparative experiments of the proposed method with various existing target detection models on the DroneVehicle and M3FD datasets show that MAF-YOLO can achieve good detection performance and robustness in complex environments. Experimental findings prove that the proposed method can effectively solve the problem of insufficient visible light modal target features in complex environments and realize accurate target detection with the fusion of infrared and visible light multimodal features.关键词:target detection;multimodal;convolutional neural network;Feature fusion;attention mechanism;visible light imaging;infrared imaging;deep learning573|2228|0更新时间:2025-12-17 - “在火星探测领域,研究人员提出了基于卷积自注意力网络的石块自动识别模型,为火星探测车安全行驶提供解决方案。”
 摘要:The Martian surface is characterized by a significant presence of rocks, whose size distribution, spatial density, and morphological characteristics are critical factors in determining the safety of landing site selection for Mars missions. These factors also directly influence the path planning and motion control of rovers during exploration activities. Moreover, the spatial distribution of rocks holds substantial value for studying the geological evolution of landing sites. However, images captured by Mars rovers often exhibit blurred boundaries between rocks and the background, as well as ambiguous textural features of the rocks themselves. These issues complicate the task of distinguishing rocks from the surrounding terrain. The scarcity of real Martian rock datasets further exacerbates these challenges, making it increasingly difficult to achieve automatic and accurate rock identification on the Martian surface. To address these challenges and achieve precise rock identification in Mars rover images, this study proposes a novel model for automatic segmentation of Martian surface rocks based on a convolutional self-attention network. The model implements pixel-level segmentation of images, adopting an encoder—decoder network architecture. The encoder utilizes a convolutional neural network to extract image features. Meanwhile, a convolutional self-attention module is incorporated to enhance the model’s ability to understand contextual information within the images and improve its rock detection performance. This module enables the model to focus effectively on important spatial features across the images, thereby capturing dependencies and contextual relationships between different regions. Finally, the model employs skip connections to facilitate feature fusion, forming a U-shaped decoder network that produces pixel-wise classification outputs, enabling precise segmentation of the images. In this paper, we present the Tianwen Mars Surface Image Dataset, a manually annotated dataset of Martian surface imagery captured by the Zhurong rover. We integrate multiple datasets, including the artificially simulated rock datasets SynMars and SimMars6K, as well as the MarsData-v2 dataset from Curiosity rover images, to conduct rigorous testing and validation of the model’s performance. Its performance is compared with that of several other advanced methods, including DeepLabv3+, UNet++, SegFormer, and MarsNet, using evaluation metrics such as average pixel accuracy, recall, and intersection over union . Results demonstrate that our proposed model excels in rock extraction, achieving accuracy and recall rates exceeding 90% on the simulated datasets. On real datasets, the model, with the highest accuracy and recall, outperforms other methods, highlighting its superior performance in rock identification. The experimental comparisons indicate that the model has the potential for accurate and reliable detection of rocks in Mars rover images, which is crucial for autonomous exploration and scientific research on Mars. The proposed convolutional self-attention module effectively combines the strengths of convolutional operations and Transformer architectures. It enhances the model’s ability to extract contextual information while retaining the capacity to capture detailed features. This dual capability not only improves the model’s segmentation accuracy in areas with dense rock clusters but also enhances its adaptability to regions with blurred boundaries. As a result, the model effectively addresses the challenges associated with accurately identifying surface rocks in the Martian environment, paving the way for reliable and efficient Mars exploration missions.关键词:Mars;Rock Extraction;convolutional neural networks;Transformer;feature extraction301|608|0更新时间:2025-12-17
摘要:The Martian surface is characterized by a significant presence of rocks, whose size distribution, spatial density, and morphological characteristics are critical factors in determining the safety of landing site selection for Mars missions. These factors also directly influence the path planning and motion control of rovers during exploration activities. Moreover, the spatial distribution of rocks holds substantial value for studying the geological evolution of landing sites. However, images captured by Mars rovers often exhibit blurred boundaries between rocks and the background, as well as ambiguous textural features of the rocks themselves. These issues complicate the task of distinguishing rocks from the surrounding terrain. The scarcity of real Martian rock datasets further exacerbates these challenges, making it increasingly difficult to achieve automatic and accurate rock identification on the Martian surface. To address these challenges and achieve precise rock identification in Mars rover images, this study proposes a novel model for automatic segmentation of Martian surface rocks based on a convolutional self-attention network. The model implements pixel-level segmentation of images, adopting an encoder—decoder network architecture. The encoder utilizes a convolutional neural network to extract image features. Meanwhile, a convolutional self-attention module is incorporated to enhance the model’s ability to understand contextual information within the images and improve its rock detection performance. This module enables the model to focus effectively on important spatial features across the images, thereby capturing dependencies and contextual relationships between different regions. Finally, the model employs skip connections to facilitate feature fusion, forming a U-shaped decoder network that produces pixel-wise classification outputs, enabling precise segmentation of the images. In this paper, we present the Tianwen Mars Surface Image Dataset, a manually annotated dataset of Martian surface imagery captured by the Zhurong rover. We integrate multiple datasets, including the artificially simulated rock datasets SynMars and SimMars6K, as well as the MarsData-v2 dataset from Curiosity rover images, to conduct rigorous testing and validation of the model’s performance. Its performance is compared with that of several other advanced methods, including DeepLabv3+, UNet++, SegFormer, and MarsNet, using evaluation metrics such as average pixel accuracy, recall, and intersection over union . Results demonstrate that our proposed model excels in rock extraction, achieving accuracy and recall rates exceeding 90% on the simulated datasets. On real datasets, the model, with the highest accuracy and recall, outperforms other methods, highlighting its superior performance in rock identification. The experimental comparisons indicate that the model has the potential for accurate and reliable detection of rocks in Mars rover images, which is crucial for autonomous exploration and scientific research on Mars. The proposed convolutional self-attention module effectively combines the strengths of convolutional operations and Transformer architectures. It enhances the model’s ability to extract contextual information while retaining the capacity to capture detailed features. This dual capability not only improves the model’s segmentation accuracy in areas with dense rock clusters but also enhances its adaptability to regions with blurred boundaries. As a result, the model effectively addresses the challenges associated with accurately identifying surface rocks in the Martian environment, paving the way for reliable and efficient Mars exploration missions.关键词:Mars;Rock Extraction;convolutional neural networks;Transformer;feature extraction301|608|0更新时间:2025-12-17 - “在高光谱图像去噪领域,本研究提出了一种新的去噪模型BSALTV,有效减少了噪声并保持了图像质量,为高光谱图像处理提供了新方法。”
 摘要:Real hyperspectral images (HSIs) are vulnerable to high-intensity mixed noise, and how to accurately model the noise is important in the subsequent processing tasks. The method of asymmetric Laplacian noise modeling has achieved a good effect in removing mixed noise and has been widely studied and applied in the field of HSI denoising. This method considers the heavy tail and asymmetry of noise and models different noises in diverse bands. However, it ignores the inherent distribution characteristics of HSI gradient base space
摘要:Real hyperspectral images (HSIs) are vulnerable to high-intensity mixed noise, and how to accurately model the noise is important in the subsequent processing tasks. The method of asymmetric Laplacian noise modeling has achieved a good effect in removing mixed noise and has been widely studied and applied in the field of HSI denoising. This method considers the heavy tail and asymmetry of noise and models different noises in diverse bands. However, it ignores the inherent distribution characteristics of HSI gradient base space - “高分七号卫星获取的湖岸岸坡地形数据在无地面观测湖泊蓄变量遥感监测中具有应用潜力。专家分析了其高程精度及影响因素,为湖泊蓄变量遥感监测提供解决方案。”
 摘要:Gaofen-7 satellite (GF-7) is the first Chinese sub-meter civil stereo mapping satellite, which can rapidly obtain Digital Surface Model (DSM) of lakeshore, and has application potential in remote sensing of lake water storage changes without ground observation. Due to the complex terrain of lakeshore, it is of great significance to quantify the accuracy and influence factors of GF-7 DSM elevation for remote sensing monitoring of lake water storage changes through GF-7 DSM. The objective of this study was to quantitatively evaluate the accuracy of GF-7 DSM elevation and its stability as well as the influencing factors of relative accuracy of GF-7 DSM elevation based on filed surveying data.To validate the elevation accuracy of GF-7 DSM at lakeshore, several elevations at point scale derived by GPS RTK or DSMs at region scale derived by UAV of 9 lakeshores in Qinghai province were collected by filed surveying. Firstly, the absolute accuracy of GF-7 DSM elevation was evaluated by comparing the differences between the elevations derived from GF-7 DSM and the measured elevation at different verification points. Secondly, the relative accuracy of GF-7 DSM elevation was estimated by the elevation biases derived from GF-7 DSM and the measured elevation differences at different verification points based on benchmark. Thirdly, the stability of GF-7 DSM elevation was evaluated by analyzing the elevation difference and correlation derived from GF-7 DSMs of different time series at same regions. Finally, the driving mechanism of terrain factors on the relative accuracy of GF-7 DSM elevation was investigated through multiple regression analysis.The results show that the elevations derived by GF-7 DSMs at different lakeshores have unstable systematic errors with poor absolute accuracy. The accuracy of GF-7 DSM elevation has significant correlation with terrain. The accuracy of GF-7 DSM elevation difference is high with a mean error less than 1.7 m. When the mean slope of lakeshore within 15°, the mean error of GF-7 DSM elevation difference is less than 1.5 m. Then, the mean error of GF-7 DSM elevation difference decreases with the increase of mean slope. The absolute accuracy of GF-7 DSM elevation can be obviously improved by correction using field surveying elevation with an overall mean error less than 0.85 m and a maximum elevation median error within 1.4 m. The mean error of GF-7 DSM elevation difference is generally within 1.25 m, its maximum median error is less than 1.6 m. The elevation accuracy of corrected GF-7 DSMs at different lakeshores do not have obvious correlation with mean slope. The accuracy of GF-7 DSM elevation difference is mainly affected by the slope of benchmark and the slope variation, among which the slope variation is the main driving factor. The weight of the slope of benchmark and the slope variation are 0.019 and 0.047, respectively. There are significant correlations between GF-7 DSMs of different time series at same region with the R2 more than 0.98.The elevation derived from certain GF-7 DSM has obvious systematic error which can be corrected by filed observations. While the GF-7 DSM elevation difference has a high relative accuracy, the uncorrected certain GF-7 DSM can also be used to estimate the lake water storage changes. The GF-7 DSMs obtained at different times have different systematic errors, which can be relatively corrected by the correlation between the different GF-7 DSMs at same region. Therefore, multiple GF-7 DSMs can be used in remote sensing monitoring of water storage changes in large lakes via mosaicking. In conclude, The GF-7 has an enormous prospect in remote sensing monitoring of lake water storage changes without ground observation.关键词:GF-7 Digital Surface Model;accuracy validation;terrain correlation;influence factors;Qinghai province;filed surveyed terrain;lakeshore115|140|0更新时间:2025-12-17
摘要:Gaofen-7 satellite (GF-7) is the first Chinese sub-meter civil stereo mapping satellite, which can rapidly obtain Digital Surface Model (DSM) of lakeshore, and has application potential in remote sensing of lake water storage changes without ground observation. Due to the complex terrain of lakeshore, it is of great significance to quantify the accuracy and influence factors of GF-7 DSM elevation for remote sensing monitoring of lake water storage changes through GF-7 DSM. The objective of this study was to quantitatively evaluate the accuracy of GF-7 DSM elevation and its stability as well as the influencing factors of relative accuracy of GF-7 DSM elevation based on filed surveying data.To validate the elevation accuracy of GF-7 DSM at lakeshore, several elevations at point scale derived by GPS RTK or DSMs at region scale derived by UAV of 9 lakeshores in Qinghai province were collected by filed surveying. Firstly, the absolute accuracy of GF-7 DSM elevation was evaluated by comparing the differences between the elevations derived from GF-7 DSM and the measured elevation at different verification points. Secondly, the relative accuracy of GF-7 DSM elevation was estimated by the elevation biases derived from GF-7 DSM and the measured elevation differences at different verification points based on benchmark. Thirdly, the stability of GF-7 DSM elevation was evaluated by analyzing the elevation difference and correlation derived from GF-7 DSMs of different time series at same regions. Finally, the driving mechanism of terrain factors on the relative accuracy of GF-7 DSM elevation was investigated through multiple regression analysis.The results show that the elevations derived by GF-7 DSMs at different lakeshores have unstable systematic errors with poor absolute accuracy. The accuracy of GF-7 DSM elevation has significant correlation with terrain. The accuracy of GF-7 DSM elevation difference is high with a mean error less than 1.7 m. When the mean slope of lakeshore within 15°, the mean error of GF-7 DSM elevation difference is less than 1.5 m. Then, the mean error of GF-7 DSM elevation difference decreases with the increase of mean slope. The absolute accuracy of GF-7 DSM elevation can be obviously improved by correction using field surveying elevation with an overall mean error less than 0.85 m and a maximum elevation median error within 1.4 m. The mean error of GF-7 DSM elevation difference is generally within 1.25 m, its maximum median error is less than 1.6 m. The elevation accuracy of corrected GF-7 DSMs at different lakeshores do not have obvious correlation with mean slope. The accuracy of GF-7 DSM elevation difference is mainly affected by the slope of benchmark and the slope variation, among which the slope variation is the main driving factor. The weight of the slope of benchmark and the slope variation are 0.019 and 0.047, respectively. There are significant correlations between GF-7 DSMs of different time series at same region with the R2 more than 0.98.The elevation derived from certain GF-7 DSM has obvious systematic error which can be corrected by filed observations. While the GF-7 DSM elevation difference has a high relative accuracy, the uncorrected certain GF-7 DSM can also be used to estimate the lake water storage changes. The GF-7 DSMs obtained at different times have different systematic errors, which can be relatively corrected by the correlation between the different GF-7 DSMs at same region. Therefore, multiple GF-7 DSMs can be used in remote sensing monitoring of water storage changes in large lakes via mosaicking. In conclude, The GF-7 has an enormous prospect in remote sensing monitoring of lake water storage changes without ground observation.关键词:GF-7 Digital Surface Model;accuracy validation;terrain correlation;influence factors;Qinghai province;filed surveyed terrain;lakeshore115|140|0更新时间:2025-12-17 - “在农业监测领域,专家提出了一种融合主被动观测数据的土壤湿度反演算法,有效提高了反演精度,为高分辨率土壤湿度制图提供解决方案。”
 摘要:High-resolution Soil Moisture (SM) data are important for crop growth monitoring and drought prediction. Accurate acquisition of SM spatiotemporal distribution and variation is essential for ensuring agricultural production management and food security. However, the majority of existing global SM data products are based on passive microwave data having a coarse resolution that is larger than 3 km, which does not meet the needs of field-scale crop monitoring. Synthetic Aperture Radar (SAR) has been widely used in SM retrieval research. However, global high-resolution SM mapping with SAR has not been fully applied in practice because of the insufficient retrieval accuracy influenced by vegetation cover, surface roughness, and existing inaccurate scattering models. This study introduces an SM retrieval algorithm that uses passive and active microwave measurements and incorporates spatiotemporal physical constraints into soil dielectric properties. In the proposed algorithm, the alpha approximation model and Change Detection (CD) inversion theorem are used for SM retrieval. Given that the number of unknown time series of the SM value is larger than that of the unknown time series of SAR observations in the CD method, underdetermined soil dielectric constant inversion remains a problem and adversely affects SM estimates. Hence, the temporal and spatial constraints of coarse resolution soil permittivity derived from passive microwave SM products are introduced for soil dielectric constant estimation. The proposed algorithm is applied to high-resolution SM retrieval and mapping over the Huanghuaihai Plain agricultural area in China to validate the effectiveness of the algorithm. Sentinel-1 backscatter measurements and SMAP 9 km daily SM data (SPL3SMP_E) from January 1 to December 31 in 2022 are collected for this study. SMAP-derived 1 km downscaled surface SM products from January to September in 2022 are employed as ground-truth measurements to evaluate the retrieval accuracy and verify the effectiveness of the proposed method. Experimental results show that 0.04 ≤ root mean square error ≤ 0.16 cm3/cm3, 0.04 ≤ mean absolute error ≤ 0.12 cm3/cm3, and 0.41 ≤ R2 ≤ 0.84. The retrieval results with incidence angle normalization show better spatial continuity compared with those of without incidence angle normalization. The proposed SM retrieval algorithm that integrates the advantages of active and passive observation data not only enables high-resolution SM retrieval but also improves the accuracy of SM retrieval results.关键词:SAR;passive microwave;Huanghuaihai Plain;soil moisture;parameter retrieval;agricultural area;high resolution136|474|0更新时间:2025-12-17
摘要:High-resolution Soil Moisture (SM) data are important for crop growth monitoring and drought prediction. Accurate acquisition of SM spatiotemporal distribution and variation is essential for ensuring agricultural production management and food security. However, the majority of existing global SM data products are based on passive microwave data having a coarse resolution that is larger than 3 km, which does not meet the needs of field-scale crop monitoring. Synthetic Aperture Radar (SAR) has been widely used in SM retrieval research. However, global high-resolution SM mapping with SAR has not been fully applied in practice because of the insufficient retrieval accuracy influenced by vegetation cover, surface roughness, and existing inaccurate scattering models. This study introduces an SM retrieval algorithm that uses passive and active microwave measurements and incorporates spatiotemporal physical constraints into soil dielectric properties. In the proposed algorithm, the alpha approximation model and Change Detection (CD) inversion theorem are used for SM retrieval. Given that the number of unknown time series of the SM value is larger than that of the unknown time series of SAR observations in the CD method, underdetermined soil dielectric constant inversion remains a problem and adversely affects SM estimates. Hence, the temporal and spatial constraints of coarse resolution soil permittivity derived from passive microwave SM products are introduced for soil dielectric constant estimation. The proposed algorithm is applied to high-resolution SM retrieval and mapping over the Huanghuaihai Plain agricultural area in China to validate the effectiveness of the algorithm. Sentinel-1 backscatter measurements and SMAP 9 km daily SM data (SPL3SMP_E) from January 1 to December 31 in 2022 are collected for this study. SMAP-derived 1 km downscaled surface SM products from January to September in 2022 are employed as ground-truth measurements to evaluate the retrieval accuracy and verify the effectiveness of the proposed method. Experimental results show that 0.04 ≤ root mean square error ≤ 0.16 cm3/cm3, 0.04 ≤ mean absolute error ≤ 0.12 cm3/cm3, and 0.41 ≤ R2 ≤ 0.84. The retrieval results with incidence angle normalization show better spatial continuity compared with those of without incidence angle normalization. The proposed SM retrieval algorithm that integrates the advantages of active and passive observation data not only enables high-resolution SM retrieval but also improves the accuracy of SM retrieval results.关键词:SAR;passive microwave;Huanghuaihai Plain;soil moisture;parameter retrieval;agricultural area;high resolution136|474|0更新时间:2025-12-17
Models and Methods
- Postal code:100190
- Tel:010-58887052 Email:nrsb@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备20021838号-9
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0