
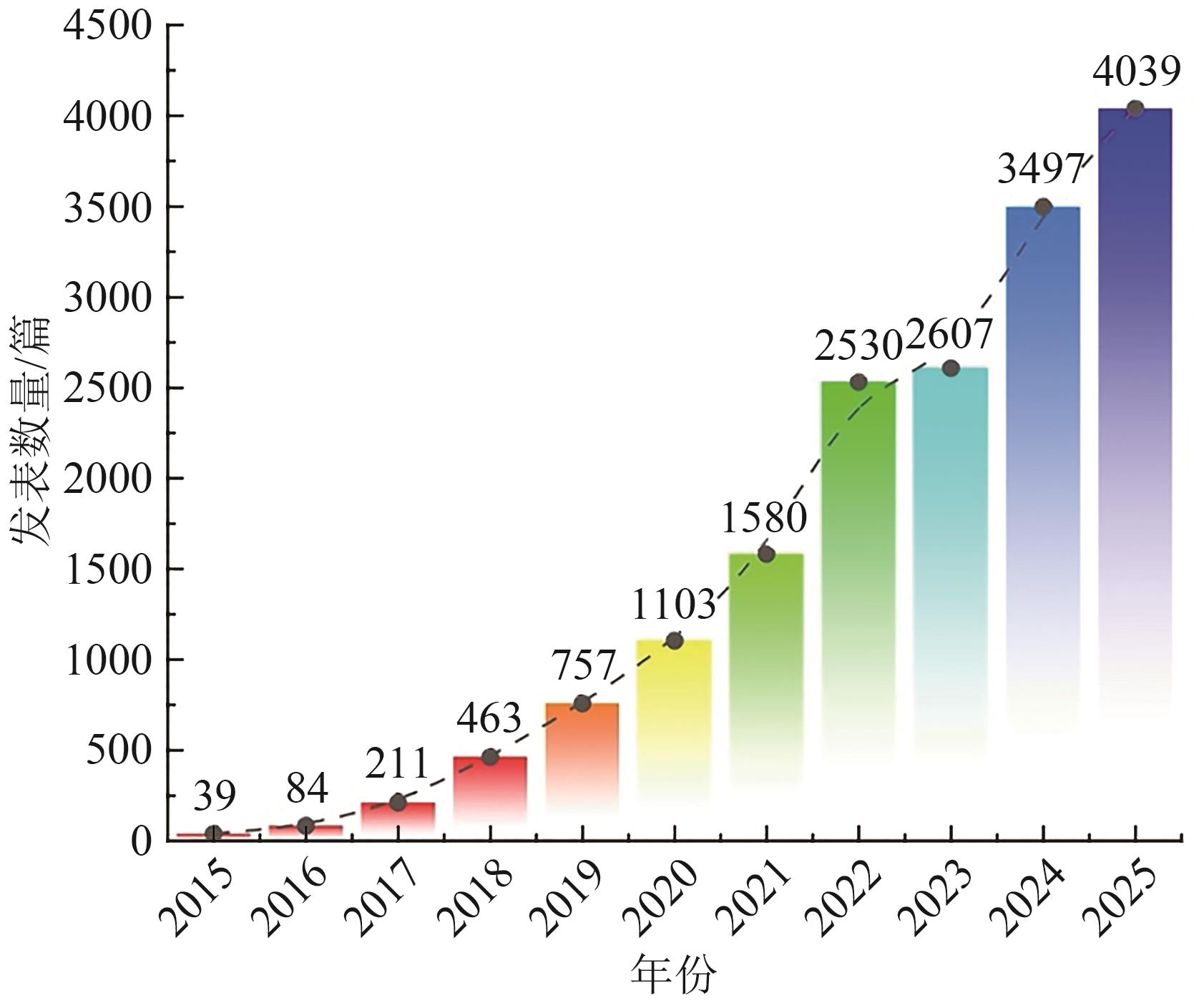
最新刊期
卷 30 , 期 2 , 2026
- “介绍了其在遥感科学领域的研究进展,专家们探索了人工智能赋能遥感科学的课题,为解决传统解译方法难以满足实际需求的问题提供了新的理论支持与技术路径。”
 摘要:Remote sensing science, through multi-platform, multi-scale, and multi-modal observations, provides key technical support for understanding the structure of the Earth system and environmental evolution. It also holds significant strategic importance in fields such as resource investigation, ecological monitoring, urban management, and disaster emergency response. The advent of advanced observation methodologies, including high-resolution optical remote sensing, Synthetic Aperture Radar (SAR), hyperspectral imaging, and lidar, has led to a proliferation of remote sensing data of unparalleled scale, variety, and continuously enhancing resolution. This paradigm shift has propelled Earth observation into a new era characterized by the management of voluminous data sets. However, the high-dimensional structural differences, spatio-temporal scale inconsistencies, and information redundancy brought about by multi-source heterogeneous data have significantly limited the traditional interpretation mode that relies on manual rules and experience-driven in terms of accuracy, efficiency, and generalization ability. Therefore, there is an urgent need to promote the transformation of remote sensing science towards an autonomous and intelligent paradigm.The advent of Artificial Intelligence (AI) has furnished a novel theoretical foundation and technical trajectory for the domain of remote sensing science. Intelligent methods, exemplified by deep learning, large models, self-supervised learning, and cross-modal representation, possess the capacity to automatically extract multi-level semantic features from substantial remote sensing data. This capability enables the efficient recognition, inference, and prediction of complex ground objects, environmental elements, and spatiotemporal dynamic processes. Presently, AI has achieved significant advancements in a variety of domains, including ground object classification, object detection, semantic segmentation, change detection, 3D scene reconstruction, and environmental element inversion. These developments have demonstrated the potential value of enhancing accuracy, generalizability, and decision-making speed in various application scenarios, such as geological remote sensing, ecological monitoring, agricultural situation assessment, urban remote sensing, and disaster damage assessment. Concurrently, novel research paradigms are emerging, characterized by the utilization of large remote sensing models and cross-modal fusion as their fundamental framework. These paradigms signify a paradigm shift in remote sensing science, transitioning from an intelligent interpretation oriented towards single tasks to an integrated intelligence oriented towards scene understanding and system cognition.Despite the rapid advancements in artificial intelligence, which are profoundly impacting the field of remote sensing science, significant challenges persist. These challenges include inadequate coordination between multi-source observation mechanisms and model representations, constrained generalizability across regions, disasters, and sensors, deficient model interpretability and credibility, and suboptimal data-driven and physical prior fusion mechanisms. In order to promote remote sensing science from “observation” to “cognition and decision support,” it is essential to build a new generation of intelligent remote sensing systems with physical consistency, dynamic adaptability, and sustainable evolution capabilities.In summary, AI is driving remote sensing science into a new phase that is centered on intelligent representation, cross-modal fusion, and knowledge-driven inference. This paper systematically reviews the fusion progress from three dimensions of observation technology, intelligent method, and typical application. It analyzes the key challenges and looks forward to the future development direction. The purpose of this analysis is to provide a reference for the construction of a unified, generalized, and reliable intelligent remote sensing theory system.关键词:remote sensing science;artificial intelligence;deep learning;cross-application;remote sensing big data;intelligent interpretation4|0|0更新时间:2026-02-13
摘要:Remote sensing science, through multi-platform, multi-scale, and multi-modal observations, provides key technical support for understanding the structure of the Earth system and environmental evolution. It also holds significant strategic importance in fields such as resource investigation, ecological monitoring, urban management, and disaster emergency response. The advent of advanced observation methodologies, including high-resolution optical remote sensing, Synthetic Aperture Radar (SAR), hyperspectral imaging, and lidar, has led to a proliferation of remote sensing data of unparalleled scale, variety, and continuously enhancing resolution. This paradigm shift has propelled Earth observation into a new era characterized by the management of voluminous data sets. However, the high-dimensional structural differences, spatio-temporal scale inconsistencies, and information redundancy brought about by multi-source heterogeneous data have significantly limited the traditional interpretation mode that relies on manual rules and experience-driven in terms of accuracy, efficiency, and generalization ability. Therefore, there is an urgent need to promote the transformation of remote sensing science towards an autonomous and intelligent paradigm.The advent of Artificial Intelligence (AI) has furnished a novel theoretical foundation and technical trajectory for the domain of remote sensing science. Intelligent methods, exemplified by deep learning, large models, self-supervised learning, and cross-modal representation, possess the capacity to automatically extract multi-level semantic features from substantial remote sensing data. This capability enables the efficient recognition, inference, and prediction of complex ground objects, environmental elements, and spatiotemporal dynamic processes. Presently, AI has achieved significant advancements in a variety of domains, including ground object classification, object detection, semantic segmentation, change detection, 3D scene reconstruction, and environmental element inversion. These developments have demonstrated the potential value of enhancing accuracy, generalizability, and decision-making speed in various application scenarios, such as geological remote sensing, ecological monitoring, agricultural situation assessment, urban remote sensing, and disaster damage assessment. Concurrently, novel research paradigms are emerging, characterized by the utilization of large remote sensing models and cross-modal fusion as their fundamental framework. These paradigms signify a paradigm shift in remote sensing science, transitioning from an intelligent interpretation oriented towards single tasks to an integrated intelligence oriented towards scene understanding and system cognition.Despite the rapid advancements in artificial intelligence, which are profoundly impacting the field of remote sensing science, significant challenges persist. These challenges include inadequate coordination between multi-source observation mechanisms and model representations, constrained generalizability across regions, disasters, and sensors, deficient model interpretability and credibility, and suboptimal data-driven and physical prior fusion mechanisms. In order to promote remote sensing science from “observation” to “cognition and decision support,” it is essential to build a new generation of intelligent remote sensing systems with physical consistency, dynamic adaptability, and sustainable evolution capabilities.In summary, AI is driving remote sensing science into a new phase that is centered on intelligent representation, cross-modal fusion, and knowledge-driven inference. This paper systematically reviews the fusion progress from three dimensions of observation technology, intelligent method, and typical application. It analyzes the key challenges and looks forward to the future development direction. The purpose of this analysis is to provide a reference for the construction of a unified, generalized, and reliable intelligent remote sensing theory system.关键词:remote sensing science;artificial intelligence;deep learning;cross-application;remote sensing big data;intelligent interpretation4|0|0更新时间:2026-02-13 - “遥感跨模态图文检索作为连接自然语言与遥感影像的桥梁,旨在构建高效的双向语义关联,是遥感数据智能化分析的关键技术。专家们全面概述了该领域的技术演进与研究现状,细致分析了主流基准数据集的特点,介绍了通用的评价指标体系,回顾了文本特征表示和遥感影像特征表示的技术突破,深入剖析了基于非跨模态预训练和基于跨模态预训练方法的原理及模型特点,并通过实验对比揭示了跨模态预训练方法的性能优势及其不同微调策略的数据适配规律。同时,总结了当前研究面临的挑战,并展望了未来的研究方向,为推动遥感跨模态图文检索技术在实际应用中的深入发展奠定了基础。”
 摘要:With the rapid development of remote sensing technology and the continuous expansion of application scenarios, efficient retrieval and intelligent utilization of massive amounts of remote sensing data have become core demands in the field of remote sensing information processing. Remote Sensing Cross-Modal Image-Text Retrieval (RS-CMITR), as a key technology connecting visual perception and language understanding, establishes semantic associations between natural language descriptions and remote sensing image content to achieve efficient bidirectional interaction between text-to-image retrieval and image-to-text retrieval. This technology breaks down modality barriers and enables precise semantic localization of remote sensing data; it also provides intelligent solutions for disaster detection, environmental monitoring, and urban planning. This study aims to systematically review the technological evolution, core methodologies, and major challenges in the RS-CMITR field and provide a comprehensive reference for in-depth research in this domain.This review systematically analyzes RS-CMITR technology, including its datasets, feature representations, model architectures, and learning paradigms. First, three mainstream benchmark datasets, namely, UCM-Captions, RSICD, and RSITMD, are introduced; their characteristics in terms of scale, scene diversity, and text annotation quality are analyzed; and the evaluation metrics, including Recall@K and mean Recall, are explained. Second, the evolution of text feature representation methods, including traditional statistical approaches and deep learning methods, as well as the development of remote sensing image feature representations from hand-crafted features to deep neural networks, are reviewed. Finally, cross-modal pretraining is used as the classification criterion. The RS-CMITR methods are classified into two major classes: methods based on noncross-modal pretraining (including dual-encoder architecture and fusion encoder architecture) and methods based on cross-modal pretraining (including full fine-tuning, prompt learning, and adapter learning). Technical principles, model characteristics, and advantages are deeply analyzed, and the performances of representative algorithms across the benchmark datasets are comprehensively compared.Experimental comparisons reveal several important findings regarding RS-CMITR methods. Compared with non-cross-modal pretraining methods, cross-modal pretraining methods consistently demonstrate superior retrieval performance across all benchmark datasets. Different fine-tuning strategies exhibit distinct data adaptability patterns. Full fine-tuning and adapter learning excel on large-scale datasets, whereas prompt learning shows advantages on small-scale datasets. These findings highlight the effectiveness of parameter-efficient fine-tuning. Dataset quality, particularly text diversity, significantly influences model performance. This review demonstrates that RS-CMITR has evolved from traditional feature engineering to deep learning-driven intelligent retrieval paradigms. Cross-modal pretraining combined with parameter-efficient fine-tuning has emerged as the mainstream technical approach.Despite significant progress in RS-CMITR technology, three core challenges remain. (1) Fine-grained semantic alignment is difficult. Existing methods struggle to capture subtle differences between similar land cover types and establish precise image-text correspondences. (2) Multisource data fusion and cross-domain generalization capabilities are insufficient. The performances of the models significantly degrade in cross-domain and cross-sensor tasks. (3) Temporal dynamic matching mechanisms are rarely studied. Current research has focused on static images, and temporal changes in land cover cannot be effectively modeled. Future research should focus on enhancing fine-grained feature representation, collaborative modeling of multisource heterogeneous data, and constructing temporal-aware dynamic alignment mechanisms to advance RS-CMITR technology from theoretical to practical applications.关键词:remote sensing images;cross-modal retrieval;image-text relationship modeling;deep learning;pre-trained models;semantic alignment;feature representation;pre-trained vision-language models4|1|0更新时间:2026-02-13
摘要:With the rapid development of remote sensing technology and the continuous expansion of application scenarios, efficient retrieval and intelligent utilization of massive amounts of remote sensing data have become core demands in the field of remote sensing information processing. Remote Sensing Cross-Modal Image-Text Retrieval (RS-CMITR), as a key technology connecting visual perception and language understanding, establishes semantic associations between natural language descriptions and remote sensing image content to achieve efficient bidirectional interaction between text-to-image retrieval and image-to-text retrieval. This technology breaks down modality barriers and enables precise semantic localization of remote sensing data; it also provides intelligent solutions for disaster detection, environmental monitoring, and urban planning. This study aims to systematically review the technological evolution, core methodologies, and major challenges in the RS-CMITR field and provide a comprehensive reference for in-depth research in this domain.This review systematically analyzes RS-CMITR technology, including its datasets, feature representations, model architectures, and learning paradigms. First, three mainstream benchmark datasets, namely, UCM-Captions, RSICD, and RSITMD, are introduced; their characteristics in terms of scale, scene diversity, and text annotation quality are analyzed; and the evaluation metrics, including Recall@K and mean Recall, are explained. Second, the evolution of text feature representation methods, including traditional statistical approaches and deep learning methods, as well as the development of remote sensing image feature representations from hand-crafted features to deep neural networks, are reviewed. Finally, cross-modal pretraining is used as the classification criterion. The RS-CMITR methods are classified into two major classes: methods based on noncross-modal pretraining (including dual-encoder architecture and fusion encoder architecture) and methods based on cross-modal pretraining (including full fine-tuning, prompt learning, and adapter learning). Technical principles, model characteristics, and advantages are deeply analyzed, and the performances of representative algorithms across the benchmark datasets are comprehensively compared.Experimental comparisons reveal several important findings regarding RS-CMITR methods. Compared with non-cross-modal pretraining methods, cross-modal pretraining methods consistently demonstrate superior retrieval performance across all benchmark datasets. Different fine-tuning strategies exhibit distinct data adaptability patterns. Full fine-tuning and adapter learning excel on large-scale datasets, whereas prompt learning shows advantages on small-scale datasets. These findings highlight the effectiveness of parameter-efficient fine-tuning. Dataset quality, particularly text diversity, significantly influences model performance. This review demonstrates that RS-CMITR has evolved from traditional feature engineering to deep learning-driven intelligent retrieval paradigms. Cross-modal pretraining combined with parameter-efficient fine-tuning has emerged as the mainstream technical approach.Despite significant progress in RS-CMITR technology, three core challenges remain. (1) Fine-grained semantic alignment is difficult. Existing methods struggle to capture subtle differences between similar land cover types and establish precise image-text correspondences. (2) Multisource data fusion and cross-domain generalization capabilities are insufficient. The performances of the models significantly degrade in cross-domain and cross-sensor tasks. (3) Temporal dynamic matching mechanisms are rarely studied. Current research has focused on static images, and temporal changes in land cover cannot be effectively modeled. Future research should focus on enhancing fine-grained feature representation, collaborative modeling of multisource heterogeneous data, and constructing temporal-aware dynamic alignment mechanisms to advance RS-CMITR technology from theoretical to practical applications.关键词:remote sensing images;cross-modal retrieval;image-text relationship modeling;deep learning;pre-trained models;semantic alignment;feature representation;pre-trained vision-language models4|1|0更新时间:2026-02-13 - “介绍了视觉语言模型在遥感领域的研究进展,相关学者构建了大规模遥感图像文本对数据集,为提升模型地理感知能力奠定基础。”
 摘要:Visual Language Models (VLMs) have achieved remarkable success across a range of multimodal tasks, including zero-shot classification, image text retrieval, image captioning, visual question answering, and visual localization. However, most existing methods are pretrained on general-purpose datasets, which often leads to suboptimal generalization performance in specialized domains such as remote sensing and medical imaging. Accordingly, a growing number of domain-specific Remote Sensing VLMs (RSVLMs) have recently been proposed. These models aim to incorporate geo-awareness by fine-tuning general VLMs using large-scale remote sensing image text pair datasets. In this study, we review and analyze the latest advancements in RSVLMs, focusing on zero-shot classification as a central task.Current VLMs can be broadly categorized into four types on the basis of their training paradigms contrastive, masked, generative, and pretrained models. Contrastive models typically consist of an image encoder and a text encoder that are jointly trained to align visual and textual representations. Masked models build upon this architecture by incorporating a multimodal encoder to facilitate cross-modal understanding through masked prediction tasks. Pretrained models further extend this framework by introducing a visual-language connector to bridge the gap between modalities. By contrast, generative models differ substantially in structure and functionality. Depending on the output modality—text or image—generative models can be divided into two subtypes, each employing distinct network architectures: One uses a text encoder, a generative network, and an image decoder. The other utilizes an image encoder, a generative network, and a text decoder.On the basis of the aforementioned classification, this study systematically categorizes existing RSVLMs and provides a detailed analysis of their core components, fine-tuning strategies, and associated datasets. Building on this analysis, we highlight several key challenges faced by current methods, including strong dependency on large-scale annotated data, high computational costs, and the absence of standardized benchmark evaluations. To address these issues, we propose several promising research directions.RSVLMs for zero-shot classification have emerged as a prominent research direction in recent years, yielding a series of notable advancements. Compared with traditional zero-shot classification methods, these models are characterized by their reliance on significantly larger-scale pretraining datasets, increased model complexity and parameter counts, and superior classification accuracy and generalization capabilities. These features are particularly valuable in the context of the rapid expansion of remote sensing data, offering substantial theoretical significance and practical applicability, as well as promising avenues for future research. This study provides a comparative analysis of the current development in RSVLMs for zero-shot classification tasks, which are primarily constructed following the paradigm of general pretraining followed by fine-tuning on remote sensing data. This approach has led to a development pattern that is driven by large-scale datasets and supported by high-performance computing resources, resulting in considerable model diversity and complexity. However, a unified evaluation framework has yet to be established. Therefore, future development of RSVLMs should focus on designing model architectures that are efficiently aligned with the unique characteristics of remote sensing data and on improving fine-tuning techniques to reduce computational demands. At the same time, efforts should be made to progressively establish a standardized and comprehensive evaluation system for these models.关键词:remote sensing intelligent interpretation;visual language model;remote sensing visual language model;model fine-tuning;multi-modal learning;image-text alignment;zero-shot classification;remote sensing dataset construction0|0|0更新时间:2026-02-13
摘要:Visual Language Models (VLMs) have achieved remarkable success across a range of multimodal tasks, including zero-shot classification, image text retrieval, image captioning, visual question answering, and visual localization. However, most existing methods are pretrained on general-purpose datasets, which often leads to suboptimal generalization performance in specialized domains such as remote sensing and medical imaging. Accordingly, a growing number of domain-specific Remote Sensing VLMs (RSVLMs) have recently been proposed. These models aim to incorporate geo-awareness by fine-tuning general VLMs using large-scale remote sensing image text pair datasets. In this study, we review and analyze the latest advancements in RSVLMs, focusing on zero-shot classification as a central task.Current VLMs can be broadly categorized into four types on the basis of their training paradigms contrastive, masked, generative, and pretrained models. Contrastive models typically consist of an image encoder and a text encoder that are jointly trained to align visual and textual representations. Masked models build upon this architecture by incorporating a multimodal encoder to facilitate cross-modal understanding through masked prediction tasks. Pretrained models further extend this framework by introducing a visual-language connector to bridge the gap between modalities. By contrast, generative models differ substantially in structure and functionality. Depending on the output modality—text or image—generative models can be divided into two subtypes, each employing distinct network architectures: One uses a text encoder, a generative network, and an image decoder. The other utilizes an image encoder, a generative network, and a text decoder.On the basis of the aforementioned classification, this study systematically categorizes existing RSVLMs and provides a detailed analysis of their core components, fine-tuning strategies, and associated datasets. Building on this analysis, we highlight several key challenges faced by current methods, including strong dependency on large-scale annotated data, high computational costs, and the absence of standardized benchmark evaluations. To address these issues, we propose several promising research directions.RSVLMs for zero-shot classification have emerged as a prominent research direction in recent years, yielding a series of notable advancements. Compared with traditional zero-shot classification methods, these models are characterized by their reliance on significantly larger-scale pretraining datasets, increased model complexity and parameter counts, and superior classification accuracy and generalization capabilities. These features are particularly valuable in the context of the rapid expansion of remote sensing data, offering substantial theoretical significance and practical applicability, as well as promising avenues for future research. This study provides a comparative analysis of the current development in RSVLMs for zero-shot classification tasks, which are primarily constructed following the paradigm of general pretraining followed by fine-tuning on remote sensing data. This approach has led to a development pattern that is driven by large-scale datasets and supported by high-performance computing resources, resulting in considerable model diversity and complexity. However, a unified evaluation framework has yet to be established. Therefore, future development of RSVLMs should focus on designing model architectures that are efficiently aligned with the unique characteristics of remote sensing data and on improving fine-tuning techniques to reduce computational demands. At the same time, efforts should be made to progressively establish a standardized and comprehensive evaluation system for these models.关键词:remote sensing intelligent interpretation;visual language model;remote sensing visual language model;model fine-tuning;multi-modal learning;image-text alignment;zero-shot classification;remote sensing dataset construction0|0|0更新时间:2026-02-13
Reviews

- “介绍了其在多模态遥感数据融合分类领域的研究进展,相关专家构建了基于Mamba结构的高光谱和LiDAR数据自适应融合协同分类网络,为提升地物识别分类精度提供了新方案。”
 摘要:HyperSpectral Images (HSIs) capture rich spectral signatures for land cover analysis but lack spatial elevation details, while Light Detection And Ranging (LiDAR) provides precise 3D geometric information. Combining these complementary modalities can significantly enhance classification accuracy. However, existing deep learning frameworks, particularly Transformer-based models, face inefficiencies due to the quadratic complexity of self-attention mechanisms when processing high-dimensional HSI data. This study aims to address these limitations by proposing a novel adaptive fusion network that leverages the linear computational efficiency of the Mamba architecture, enabling efficient and accurate joint classification of HSI and LiDAR data.We propose AFMamba, an adaptive fusion collaborative classification network based on the Mamba architecture. The network features three key components: A dual-branch feature extraction module independently encodes HSI spectral-spatial features and LiDAR elevation information. A stackable dual-channel collaborative attention module built upon Mamba blocks captures long-range dependencies across modalities while enforcing parameter sharing to enhance feature consistency and mutual learning. An adaptive fusion block (AF) dynamically weighs multimodal features through learnable parameters, optimized via layer normalization.By integrating Mamba’s selective state-space model, the network achieves linear computational complexity, efficiently modeling global dependencies without sacrificing spatial-spectral details. The parallel training architecture further reduces computational bottlenecks.Extensive experiments on three benchmark datasets—Trento, Houston 2013, and MUUFL—demonstrate AFMamba’s superiority. The proposed method achieves state-of-the-art overall accuracies of 99.33%, 91.74%, and 94.94%, respectively, outperforming Transformer-based models (MFT, MIViT) and Mamba variants (HLMamba, SpectralMamba).AFMamba establishes a new paradigm for efficient and accurate fusion of HSI and LiDAR data by integrating Mamba’s linear-time modeling capability with parameter-shared cross-modal attention. The method effectively addresses the computational inefficiency of Transformers while achieving superior classification performance through adaptive feature fusion and global dependency learning. Future work will extend this framework to semisupervised scenarios and explore its applicability to other multimodal remote sensing tasks, such as change detection and target recognition.关键词:remote sensing image classification;collaborative classification;adaptive fusion;Mamba architecture;parameter sharing;hyperspectral image;LiDAR;Multimodal data fusion0|0|0更新时间:2026-02-13
摘要:HyperSpectral Images (HSIs) capture rich spectral signatures for land cover analysis but lack spatial elevation details, while Light Detection And Ranging (LiDAR) provides precise 3D geometric information. Combining these complementary modalities can significantly enhance classification accuracy. However, existing deep learning frameworks, particularly Transformer-based models, face inefficiencies due to the quadratic complexity of self-attention mechanisms when processing high-dimensional HSI data. This study aims to address these limitations by proposing a novel adaptive fusion network that leverages the linear computational efficiency of the Mamba architecture, enabling efficient and accurate joint classification of HSI and LiDAR data.We propose AFMamba, an adaptive fusion collaborative classification network based on the Mamba architecture. The network features three key components: A dual-branch feature extraction module independently encodes HSI spectral-spatial features and LiDAR elevation information. A stackable dual-channel collaborative attention module built upon Mamba blocks captures long-range dependencies across modalities while enforcing parameter sharing to enhance feature consistency and mutual learning. An adaptive fusion block (AF) dynamically weighs multimodal features through learnable parameters, optimized via layer normalization.By integrating Mamba’s selective state-space model, the network achieves linear computational complexity, efficiently modeling global dependencies without sacrificing spatial-spectral details. The parallel training architecture further reduces computational bottlenecks.Extensive experiments on three benchmark datasets—Trento, Houston 2013, and MUUFL—demonstrate AFMamba’s superiority. The proposed method achieves state-of-the-art overall accuracies of 99.33%, 91.74%, and 94.94%, respectively, outperforming Transformer-based models (MFT, MIViT) and Mamba variants (HLMamba, SpectralMamba).AFMamba establishes a new paradigm for efficient and accurate fusion of HSI and LiDAR data by integrating Mamba’s linear-time modeling capability with parameter-shared cross-modal attention. The method effectively addresses the computational inefficiency of Transformers while achieving superior classification performance through adaptive feature fusion and global dependency learning. Future work will extend this framework to semisupervised scenarios and explore its applicability to other multimodal remote sensing tasks, such as change detection and target recognition.关键词:remote sensing image classification;collaborative classification;adaptive fusion;Mamba architecture;parameter sharing;hyperspectral image;LiDAR;Multimodal data fusion0|0|0更新时间:2026-02-13 - “遥感图像指向分割领域迎来新突破,相关专家提出Enti-CroM方法,通过实体引导跨模态交互,有效解决地物混淆及模态差异问题,为遥感图像智能分析提供新思路。”
 摘要:Remote Sensing Image Referring Segmentation (RRSIS) aims to accurately locate and delineate specific regions within high-resolution remote sensing imagery on the basis of natural language referring expressions and ultimately achieve pixel-level semantic interpretation. This task critically bridges user demands and intelligent geospatial information analysis. However, compared with natural scene referential segmentation, RRSIS presents two unique challenges.(1) Relatively low contrast between targets and their surroundings often leads to a semantic dispersion phenomenon, where the segmentation mask covers irrelevant areas.(2) Substantial cross-modal semantic gaps exist between visual and textual representations. Conventional cross-modal attention mechanisms tend to rely on coarse feature alignments, which are insufficient for fine-grained geographical boundary delineation.The objective of this study is to design a robust and generalizable framework that can effectively mitigate semantic dispersion, narrow the modality gap, and achieve precise alignment between entity-level textual descriptions and complex geospatial visual features in RRSIS tasks.The proposed Enti-CroM, an entity-guided cross-modal interaction framework tailored for RRSIS, is adopted in this study.Entity-Guided Self-Reasoning (SEG) module: Motivated by the Segment Anything Model (SAM), the SEG module injects fine-grained entity priors into the model by leveraging spatial-structural constraints. A self-reasoning process generates robust and coherent entity prompts, which are integrated with visual and textual embeddings to form a trimodal entity–vision–text feature cube. Hierarchical Modality Interaction (HMI) mechanism: Parameter-Free Mutual Activation (PFMA): PFMA is a neuroscience-inspired and spatially aware mutual modulation approach that computes positionwise semantic similarity between modalities without introducing additional learnable parameters. PFMA enables efficient and precise semantic information propagation, suppresses irrelevant background interference, and reduces modality misalignment. Entity-Guided Cross-Attention (EGCA): EGCA incorporates the entity prior as an attention guide to refine the interaction between textual and visual streams and ultimately enhance the ability of the model to represent irregular and fine-grained geographical boundaries. The overall architecture decouples cross-modal semantic propagation from fine-grained spatial dependency modeling to ensure high-level semantic consistency and spatial precision.Extensive experiments were conducted on two benchmark datasets, namely, RefSegRS and RRSIS-D, which are widely used for RRSIS evaluation. Performance was assessed via the mean intersection-over-union (mIoU) metric. Compared with the strongest existing state-of-the-art method, Enti-CroM achieved absolute mIoU improvements of +3.23% on RefSegRS and +2.62% on RRSIS-D. Ablation studies further confirmed the effectiveness of each component. The SEG module alone significantly improved target localization and robustness to background clutter. The HMI mechanism, particularly PFMA, improved modality alignment and suppression of semantic noise, whereas EGCA improved boundary representation in complex spatial contexts. Qualitative visual comparisons demonstrated that Enti-CroM delivers sharper object boundaries, more accurate correspondence to the referring expressions, and fewer false positive regions, especially in heterogeneous landscapes such as urban areas and agricultural mosaics.This work addresses two longstanding challenges in RRSIS, namely, semantic dispersion and cross-modal gaps, by integrating entity-guided priors and a hierarchical modality interaction strategy. Incorporating spatially grounded entity cues and explicit, fine-grained semantic alignment allows Enti-CroM to substantially enhance segmentation accuracy and robustness in complex remote sensing scenes. The proposed framework not only sets new benchmarks on two challenging datasets but also offers a general paradigm for entity-aware multimodal analysis in remote sensing. Despite the advantages of the Enti-CroM, it still faces certain limitations, such as reliance on the quality of entity priors and increased computational demand for ultrahigh-resolution imagery. Future work will focus on three aspects: (1) developing adaptive or self-supervised entity prior generation mechanisms to reduce dependency on external annotations; (2) incorporating model compression and acceleration for large-scale deployment; and (3) extending the framework to integrate additional modalities, such as hyperspectral and SAR data, and broaden earth observation applications.关键词:remote sensing imagery;referring segmentation;cross-modal interaction;SAM;entity awareness;attention mechanisms;spatial-structural constraints2|0|0更新时间:2026-02-13
摘要:Remote Sensing Image Referring Segmentation (RRSIS) aims to accurately locate and delineate specific regions within high-resolution remote sensing imagery on the basis of natural language referring expressions and ultimately achieve pixel-level semantic interpretation. This task critically bridges user demands and intelligent geospatial information analysis. However, compared with natural scene referential segmentation, RRSIS presents two unique challenges.(1) Relatively low contrast between targets and their surroundings often leads to a semantic dispersion phenomenon, where the segmentation mask covers irrelevant areas.(2) Substantial cross-modal semantic gaps exist between visual and textual representations. Conventional cross-modal attention mechanisms tend to rely on coarse feature alignments, which are insufficient for fine-grained geographical boundary delineation.The objective of this study is to design a robust and generalizable framework that can effectively mitigate semantic dispersion, narrow the modality gap, and achieve precise alignment between entity-level textual descriptions and complex geospatial visual features in RRSIS tasks.The proposed Enti-CroM, an entity-guided cross-modal interaction framework tailored for RRSIS, is adopted in this study.Entity-Guided Self-Reasoning (SEG) module: Motivated by the Segment Anything Model (SAM), the SEG module injects fine-grained entity priors into the model by leveraging spatial-structural constraints. A self-reasoning process generates robust and coherent entity prompts, which are integrated with visual and textual embeddings to form a trimodal entity–vision–text feature cube. Hierarchical Modality Interaction (HMI) mechanism: Parameter-Free Mutual Activation (PFMA): PFMA is a neuroscience-inspired and spatially aware mutual modulation approach that computes positionwise semantic similarity between modalities without introducing additional learnable parameters. PFMA enables efficient and precise semantic information propagation, suppresses irrelevant background interference, and reduces modality misalignment. Entity-Guided Cross-Attention (EGCA): EGCA incorporates the entity prior as an attention guide to refine the interaction between textual and visual streams and ultimately enhance the ability of the model to represent irregular and fine-grained geographical boundaries. The overall architecture decouples cross-modal semantic propagation from fine-grained spatial dependency modeling to ensure high-level semantic consistency and spatial precision.Extensive experiments were conducted on two benchmark datasets, namely, RefSegRS and RRSIS-D, which are widely used for RRSIS evaluation. Performance was assessed via the mean intersection-over-union (mIoU) metric. Compared with the strongest existing state-of-the-art method, Enti-CroM achieved absolute mIoU improvements of +3.23% on RefSegRS and +2.62% on RRSIS-D. Ablation studies further confirmed the effectiveness of each component. The SEG module alone significantly improved target localization and robustness to background clutter. The HMI mechanism, particularly PFMA, improved modality alignment and suppression of semantic noise, whereas EGCA improved boundary representation in complex spatial contexts. Qualitative visual comparisons demonstrated that Enti-CroM delivers sharper object boundaries, more accurate correspondence to the referring expressions, and fewer false positive regions, especially in heterogeneous landscapes such as urban areas and agricultural mosaics.This work addresses two longstanding challenges in RRSIS, namely, semantic dispersion and cross-modal gaps, by integrating entity-guided priors and a hierarchical modality interaction strategy. Incorporating spatially grounded entity cues and explicit, fine-grained semantic alignment allows Enti-CroM to substantially enhance segmentation accuracy and robustness in complex remote sensing scenes. The proposed framework not only sets new benchmarks on two challenging datasets but also offers a general paradigm for entity-aware multimodal analysis in remote sensing. Despite the advantages of the Enti-CroM, it still faces certain limitations, such as reliance on the quality of entity priors and increased computational demand for ultrahigh-resolution imagery. Future work will focus on three aspects: (1) developing adaptive or self-supervised entity prior generation mechanisms to reduce dependency on external annotations; (2) incorporating model compression and acceleration for large-scale deployment; and (3) extending the framework to integrate additional modalities, such as hyperspectral and SAR data, and broaden earth observation applications.关键词:remote sensing imagery;referring segmentation;cross-modal interaction;SAM;entity awareness;attention mechanisms;spatial-structural constraints2|0|0更新时间:2026-02-13 -
Multitask learning for unsupervised domain adaptive semantic segmentation of remote sensing images AI导读
“遥感图像语义分割在土地覆盖与利用分类、城市规划以及变化检测等领域具有重要作用。域自适应技术作为一种极具潜力的无监督学习方法,该技术大大推动了遥感图像语义分割的发展。然而,现有模型尚基于单任务来学习,学习获得的分割特征不够充分,导致在分割过程中难以准确识别遥感图像中的复杂区域。为解决这一问题,专家提出了一种多任务学习域自适应语义分割网络MTLDANet,该网络通过协同学习遥感图像中的语义信息与高程信息,来提升分割特征的学习能力。”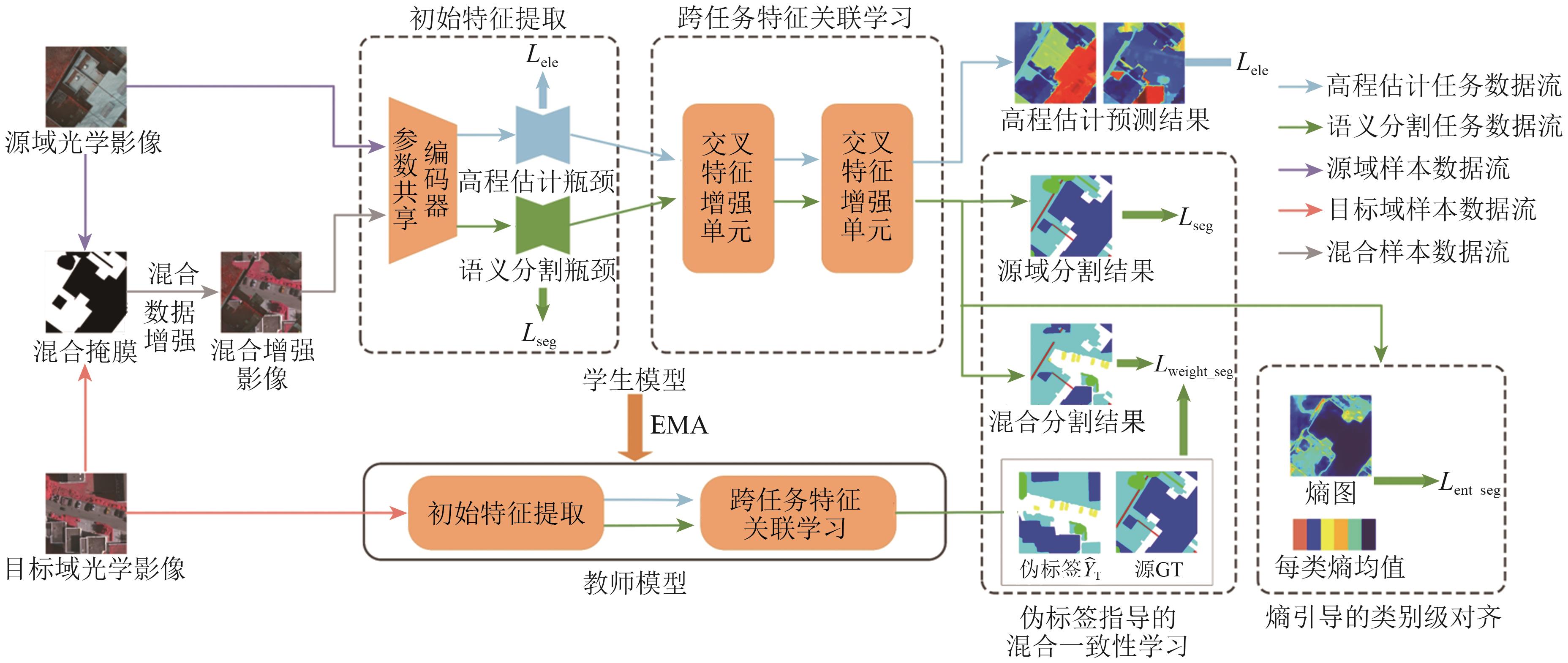 摘要:Semantic segmentation of remote sensing images (RSIs) plays a crucial role in land cover and land use classification, urban planning, and change detection. Domain adaptation, as a promising unsupervised learning approach, has significantly accelerated the advancement of RSI segmentation.. However, current models often rely on the limited feature learning capability of single-task approaches, making hard-to-classify regions in RSIs difficult to distinguish accurately. To address this issue, this study proposes a multi-task learning domain adaptive network (MTLDANet), which jointly learns semantic and elevation information in RSIs, improving segmentation performance.The method feeds task-specific semantic and elevation features into a cross-task feature correlation learning module to explore latent correlations between tasks, thereby enhancing task-specific feature representations. A hybrid consistency learning module, guided by pseudo-label, is employed to improve pseudo-label quality and achieve global domain alignment. Additionally, entropy-guided category-level alignment module enhances the separability of challenging categories.The proposed method is evaluated on four cross-scene RSI segmentation experiments using ISPRS 2D and US3D datasets.Results show that the method outperforms existing domain adaptation approaches, demonstrating significant advantages in various complex cross-domain scenarios.关键词:semantic segmentation;unsupervised domain adaptation;remote sensing imagery;Multi-task learning;elevation information;semantic information;pseudo-label;Entropy0|0|0更新时间:2026-02-13
摘要:Semantic segmentation of remote sensing images (RSIs) plays a crucial role in land cover and land use classification, urban planning, and change detection. Domain adaptation, as a promising unsupervised learning approach, has significantly accelerated the advancement of RSI segmentation.. However, current models often rely on the limited feature learning capability of single-task approaches, making hard-to-classify regions in RSIs difficult to distinguish accurately. To address this issue, this study proposes a multi-task learning domain adaptive network (MTLDANet), which jointly learns semantic and elevation information in RSIs, improving segmentation performance.The method feeds task-specific semantic and elevation features into a cross-task feature correlation learning module to explore latent correlations between tasks, thereby enhancing task-specific feature representations. A hybrid consistency learning module, guided by pseudo-label, is employed to improve pseudo-label quality and achieve global domain alignment. Additionally, entropy-guided category-level alignment module enhances the separability of challenging categories.The proposed method is evaluated on four cross-scene RSI segmentation experiments using ISPRS 2D and US3D datasets.Results show that the method outperforms existing domain adaptation approaches, demonstrating significant advantages in various complex cross-domain scenarios.关键词:semantic segmentation;unsupervised domain adaptation;remote sensing imagery;Multi-task learning;elevation information;semantic information;pseudo-label;Entropy0|0|0更新时间:2026-02-13 - “介绍了其在雾天遥感图像目标检测领域的研究进展,相关专家建立了级联学习的雾下目标检测方法CL-FODM体系,为解决雾天条件下目标检测性能下降问题提供了有效解决方案。”
 摘要:Under foggy conditions, atmospheric scattering reduces the illumination intensity in images, which leads to a decrease in the contrast of remote sensing images and affects the performance of object detection models. Existing research has addressed this issue through two strategies: training models on foggy data or using image dehazing as a preprocessing step. However, the dehazing process can result in loss of feature, and it is difficult to ensure a consistently positive correlation between dehazing results and object detection tasks, i.e., the dehazing results are beneficial for object detection. To address this issue, this study proposes a cascade learning foggy object detection method (CL-FODM). This method establishes a lightweight dehazing subnetwork combining CNN and Transformer, which can obtain clear dehazed features and provide salient semantic information for the object detection task. A multitask loss function guided by feature perception is constructed to precisely mine discriminative target semantic features at the feature level, achieving collaborative optimization between dehazing and object detection and solving the semantic inconsistency between low- and high-level tasks. Experimental results show that the CL-FODM proposed in this paper outperforms the original model and the cascaded model in terms of evaluation metrics and visual detection effects.关键词:remote sensing imagery;object detection;Dehazing Model;deep learning;Cascade Learning0|0|0更新时间:2026-02-13
摘要:Under foggy conditions, atmospheric scattering reduces the illumination intensity in images, which leads to a decrease in the contrast of remote sensing images and affects the performance of object detection models. Existing research has addressed this issue through two strategies: training models on foggy data or using image dehazing as a preprocessing step. However, the dehazing process can result in loss of feature, and it is difficult to ensure a consistently positive correlation between dehazing results and object detection tasks, i.e., the dehazing results are beneficial for object detection. To address this issue, this study proposes a cascade learning foggy object detection method (CL-FODM). This method establishes a lightweight dehazing subnetwork combining CNN and Transformer, which can obtain clear dehazed features and provide salient semantic information for the object detection task. A multitask loss function guided by feature perception is constructed to precisely mine discriminative target semantic features at the feature level, achieving collaborative optimization between dehazing and object detection and solving the semantic inconsistency between low- and high-level tasks. Experimental results show that the CL-FODM proposed in this paper outperforms the original model and the cascaded model in terms of evaluation metrics and visual detection effects.关键词:remote sensing imagery;object detection;Dehazing Model;deep learning;Cascade Learning0|0|0更新时间:2026-02-13 - “多时相高光谱图像在变化检测领域应用广泛,但传统算法依赖大量标记样本,成本过高。专家提出JCDS2AN网络,通过多尺度空谱注意力块和差异特征引导策略,有效缓解样本受限问题,经实验验证,该方法优于其他高光谱变化检测方法。”
 摘要:Multitemporal hyperspectral images have a wide range of applications in change detection given their rich spectral features and image details. Traditional hyperspectral change detection (HSICD) algorithms based on supervised learning often rely on a large number of labeled samples, which requires a large sample annotation cost. In recent years, although research has explored the problem of change detection under limited labeled samples, many aspects need further exploration. Existing methods often fail to fully tap into the potential of limited labeled samples, and shortcomings exist in the extraction of changing features. Therefore, we develop a new network architecture aimed at effectively utilizing limited labeled samples and focusing on extracting differential features to enhance information related to changes.In this paper, we propose a joint central difference feature and spatial-spectral attention network (JCDS2AN) for HSICD, which can alleviate the fluctuation in changing features under sample constraints and learn representative changing features. In JCDS2AN, a multiscale spatial-spectral attention block is designed to capture multiscale spatial and spectral features, and a differential center pixel exchange strategy guided by differential features is proposed to achieve efficient information exchange between differential features and two temporal features.Experimental results on three publicly available hyperspectral image datasets show that the proposed JCDS2AN outperforms the state-of-the-art methods in HSICD. When utilizing only 1% of the training samples, the method achieved optimal Kappa and OA of 95.90% and 98.30%, respectively, on the Farmland dataset. Ablation experiments were conducted for each proposed module to demonstrate their effectiveness. This approach is capable of extracting discriminative deep change semantic information, with both qualitative and quantitative results surpassing those of other advanced networks.关键词:hyperspectral image;remote sensing images;change detection;Multi-scale Features;differential feature guidance;center pixel0|0|0更新时间:2026-02-13
摘要:Multitemporal hyperspectral images have a wide range of applications in change detection given their rich spectral features and image details. Traditional hyperspectral change detection (HSICD) algorithms based on supervised learning often rely on a large number of labeled samples, which requires a large sample annotation cost. In recent years, although research has explored the problem of change detection under limited labeled samples, many aspects need further exploration. Existing methods often fail to fully tap into the potential of limited labeled samples, and shortcomings exist in the extraction of changing features. Therefore, we develop a new network architecture aimed at effectively utilizing limited labeled samples and focusing on extracting differential features to enhance information related to changes.In this paper, we propose a joint central difference feature and spatial-spectral attention network (JCDS2AN) for HSICD, which can alleviate the fluctuation in changing features under sample constraints and learn representative changing features. In JCDS2AN, a multiscale spatial-spectral attention block is designed to capture multiscale spatial and spectral features, and a differential center pixel exchange strategy guided by differential features is proposed to achieve efficient information exchange between differential features and two temporal features.Experimental results on three publicly available hyperspectral image datasets show that the proposed JCDS2AN outperforms the state-of-the-art methods in HSICD. When utilizing only 1% of the training samples, the method achieved optimal Kappa and OA of 95.90% and 98.30%, respectively, on the Farmland dataset. Ablation experiments were conducted for each proposed module to demonstrate their effectiveness. This approach is capable of extracting discriminative deep change semantic information, with both qualitative and quantitative results surpassing those of other advanced networks.关键词:hyperspectral image;remote sensing images;change detection;Multi-scale Features;differential feature guidance;center pixel0|0|0更新时间:2026-02-13 - “从遥感图像中自动提取道路在智慧城市、智慧交通和自动驾驶等领域有着广泛的应用前景。然而,从高分辨率遥感图像中自动提取的道路存在碎片化、连通性差等问题,提取完整的道路仍然具有挑战性。为此,相关专家提出了一种改进的编码器—解码器网络SAMSNet(Split-Attention and Multi-Scale Attention Network)。该网络采用Split-Attention Network (ResNeSt-50)作为编码器,通过跨通道提取图像的语义信息以实现高质量的特征表示;引入级联并行的空洞卷积块,在扩大感受野的同时提高网络对多尺度上下文信息的感知能力;在跳跃连接部分引入多尺度通道注意力模块MS-CAM(Multi-Scale Channel Attention Module),同时关注分布全局的和局部的道路信息,帮助网络识别和检测极端尺度变化下的道路。并在DeepGlobe Road数据集、Massachusetts Road数据集和GRSet数据集上进行实验验证,将SAMSNet与其他9种主流模型进行对比。验证结果表明,SAMSNet在3个公开数据集上的IoU和F1-score等多项评价指标均优于其他对比模型,取得了最优的提取结果。”
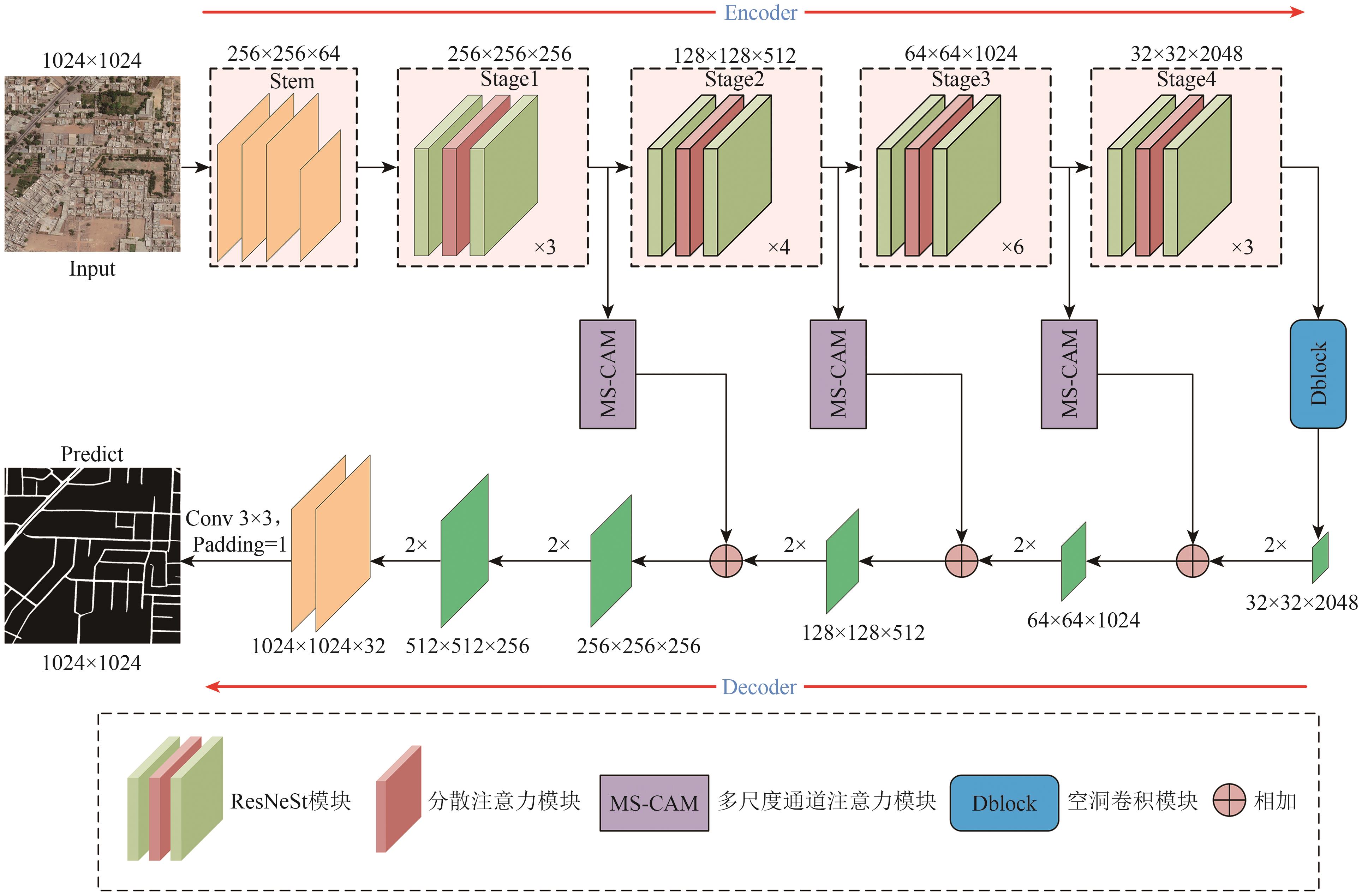 摘要:Automatic road extraction from high-resolution remote sensing images plays a crucial role in applications such as smart cities, intelligent transportation, and autonomous driving. However, existing methods often suffer from issues like fragmentation and poor connectivity in the extracted road networks, especially under complex scenarios with occlusions, shadows, and large-scale variations. This study aims to develop a robust deep learning model capable of extracting continuous and complete road networks from high-resolution remote sensing imagery by effectively integrating multiscale contextual information and attention mechanisms.An improved encoder-decoder network named Split-Attention and Multi-Scale Attention Network (SAMSNet) is proposed. The encoder is based on ResNeSt-50, which utilizes a split-attention mechanism to enhance cross-channel feature interaction and capture rich semantic representations. A cascaded parallel dilated convolution block (Dblock) is introduced in the central part of the network to expand the receptive field and aggregate multiscale context without losing spatial details. Furthermore, a multiscale channel attention module (MS-CAM) is incorporated into the skip connections to simultaneously emphasize global and local road features, improving the model’s ability to handle extreme scale variations. The network is trained using a combined loss function of binary cross-entropy and Dice loss to address class imbalance and emphasize boundary accuracy.Extensive experiments were conducted on three public road extraction datasets DeepGlobe, Massachusetts, and GRSet. SAMSNet achieved state-of-the-art performance across all datasets. On the DeepGlobe dataset, it attained an IoU of 74.48% and an F1-score of 85.37%, significantly outperforming other models such as U-Net, D-LinkNet, and transformer-based approaches. Similar improvements were observed on the Massachusetts dataset, with IoU and F1-score reaching 66.61% and 79.96%, respectively. Transfer learning experiments on the GRSet dataset further demonstrated the strong generalization capability of SAMSNet, where it achieved the highest IoU (55.55%) and F1-score (60.71%) among all compared models. Ablation studies confirmed the individual contributions of the Dblock and MS-CAM modules to the overall performance.SAMSNet effectively integrates split-attention, multiscale dilated convolution, and channel attention mechanisms to improve the accuracy, connectivity, and completeness of road extraction from high-resolution remote sensing images. The proposed model shows strong performance across diverse datasets and complex scenarios, indicating its robustness and generalization ability. However, the model’s high computational complexity may limit its deployment in real-time applications. Future work will focus on developing lighter versions of the model and exploring joint extraction of road segmentation and centerline detection.关键词:remote sensing images;road extraction;semantic segmentation;ResNeSt-50;Dispersed Attention;Multi-Scale Channel Attention;dilated convolution0|0|0更新时间:2026-02-13
摘要:Automatic road extraction from high-resolution remote sensing images plays a crucial role in applications such as smart cities, intelligent transportation, and autonomous driving. However, existing methods often suffer from issues like fragmentation and poor connectivity in the extracted road networks, especially under complex scenarios with occlusions, shadows, and large-scale variations. This study aims to develop a robust deep learning model capable of extracting continuous and complete road networks from high-resolution remote sensing imagery by effectively integrating multiscale contextual information and attention mechanisms.An improved encoder-decoder network named Split-Attention and Multi-Scale Attention Network (SAMSNet) is proposed. The encoder is based on ResNeSt-50, which utilizes a split-attention mechanism to enhance cross-channel feature interaction and capture rich semantic representations. A cascaded parallel dilated convolution block (Dblock) is introduced in the central part of the network to expand the receptive field and aggregate multiscale context without losing spatial details. Furthermore, a multiscale channel attention module (MS-CAM) is incorporated into the skip connections to simultaneously emphasize global and local road features, improving the model’s ability to handle extreme scale variations. The network is trained using a combined loss function of binary cross-entropy and Dice loss to address class imbalance and emphasize boundary accuracy.Extensive experiments were conducted on three public road extraction datasets DeepGlobe, Massachusetts, and GRSet. SAMSNet achieved state-of-the-art performance across all datasets. On the DeepGlobe dataset, it attained an IoU of 74.48% and an F1-score of 85.37%, significantly outperforming other models such as U-Net, D-LinkNet, and transformer-based approaches. Similar improvements were observed on the Massachusetts dataset, with IoU and F1-score reaching 66.61% and 79.96%, respectively. Transfer learning experiments on the GRSet dataset further demonstrated the strong generalization capability of SAMSNet, where it achieved the highest IoU (55.55%) and F1-score (60.71%) among all compared models. Ablation studies confirmed the individual contributions of the Dblock and MS-CAM modules to the overall performance.SAMSNet effectively integrates split-attention, multiscale dilated convolution, and channel attention mechanisms to improve the accuracy, connectivity, and completeness of road extraction from high-resolution remote sensing images. The proposed model shows strong performance across diverse datasets and complex scenarios, indicating its robustness and generalization ability. However, the model’s high computational complexity may limit its deployment in real-time applications. Future work will focus on developing lighter versions of the model and exploring joint extraction of road segmentation and centerline detection.关键词:remote sensing images;road extraction;semantic segmentation;ResNeSt-50;Dispersed Attention;Multi-Scale Channel Attention;dilated convolution0|0|0更新时间:2026-02-13
Remote Sensing Intelligent Interpretation
- “专家提出基于KAN的高光谱Rrs重构模型,利用卫星遥感数据训练,从多光谱Rrs中重建高光谱Rrs,性能优于传统模型,为复杂水体遥感反演提供新思路。”
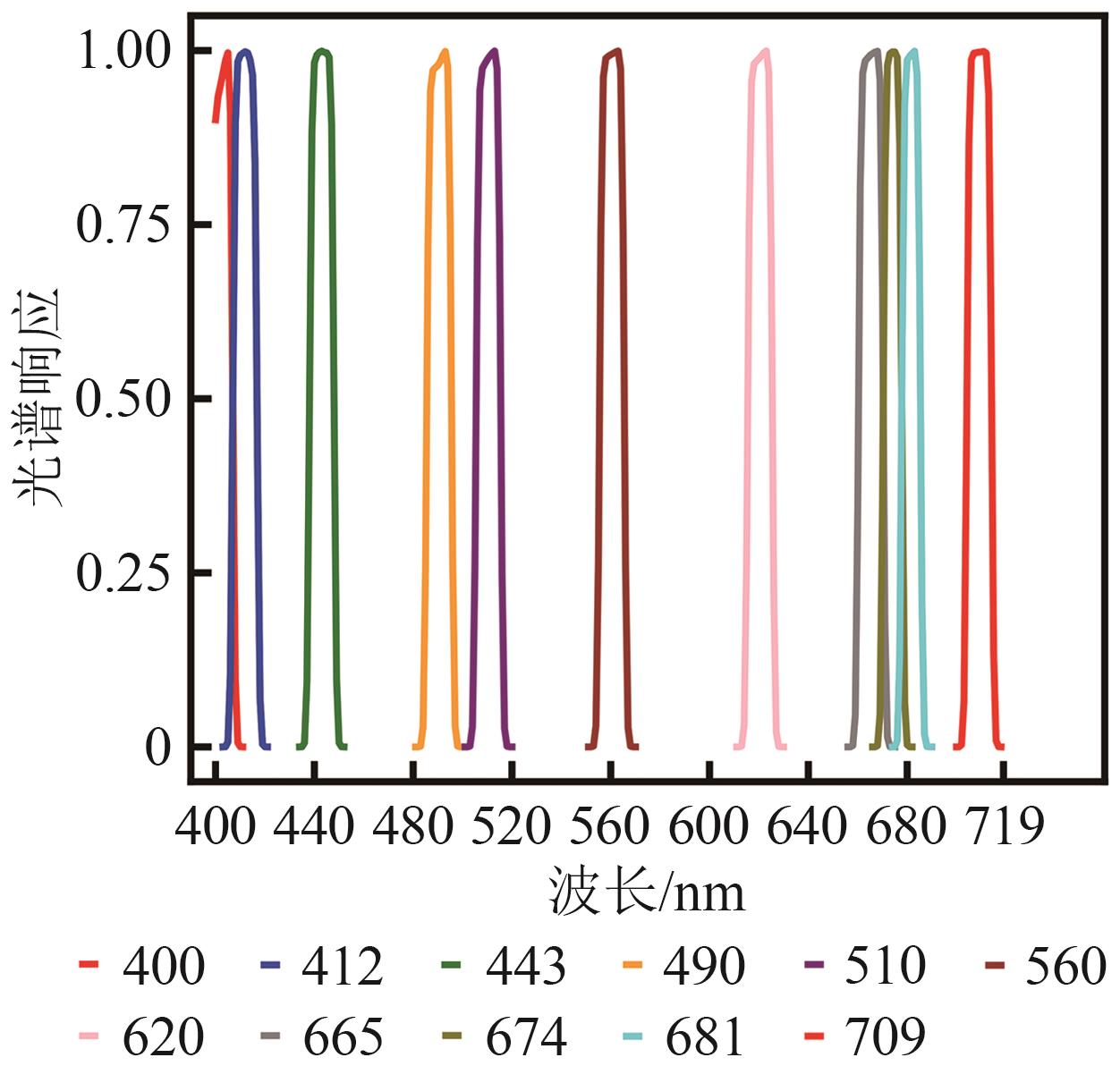 摘要:To address the challenges in acquiring hyperspectral remote sensing reflectance (Rrs) data and the limitations of existing spectral reconstruction methods, including their reliance on in-situ measurements, weak generalization ability, and insufficient accuracy in optically complex coastal waters, this study proposes a novel deep learning model based on the Kolmogorov-Arnold Network (KAN). The model is designed to directly exploit widely available multispectral satellite observations to efficiently reconstruct continuous hyperspectral Rrs that closely match the characteristics of true measurements, thereby overcoming the bottlenecks of traditional approaches and improving remote sensing inversion performance in complex nearshore environments.The proposed method adopts an end-to-end nonlinear modeling framework within the KAN architecture, incorporating learnable nonlinear activation functions to flexibly capture complex local nonlinear relationships in the input data. This approach enables accurate reconstruction of continuous hyperspectral Rrs from multispectral inputs, with spectral distributions highly consistent with actual observations. In this work, Level-2 Rrs products from the Hyperspectral Imager for the Coastal Ocean were used as training samples. These products were resampled in accordance with the spectral response functions of six mainstream multispectral sensors (S3A OLCI, MERIS, MODIS, SeaWiFS, S2A MSI, and OLI) to generate “multispectral-hyperspectral” data pairs for model training. The approach eliminates the need for in-situ or optical simulation data, relying solely on remote sensing observations for training and modeling, thus greatly enhancing model generality and practicality.Experimental results demonstrate that the KAN model achieved superior reconstruction accuracy (mean R2 > 0.9982) and robustness across all six sensors compared with benchmark models. It not only reproduced the overall spectral shape with high fidelity but also exhibited strong detail-capturing capability in critical regions with missing or sparse sensor bands, such as the red-edge region beyond 680 nm, producing reconstructed curves nearly identical to the original spectra. In downstream chlorophyll-a inversion applications, the use of KAN-reconstructed data significantly improved retrieval accuracy over original multispectral inputs, reducing RMSE by approximately 16.13% and increasing R2 by 3.30%. The advantages were particularly evident in high-concentration waters, effectively overcoming the limitations of multispectral sensors.Overall, the proposed KAN-based hyperspectral Rrs reconstruction model successfully breaks the dependency bottleneck of traditional methods on in-situ or simulated data, offering a highly accurate and generalizable universal solution. By generating high-quality continuous spectra from existing multispectral datasets, it substantially enhances the performance and accuracy of water quality parameter retrieval in complex aquatic environments. The model serves as a powerful data augmentation tool for aquatic remote sensing and a novel technical pathway for leveraging vast archives of historical multispectral satellite data to enable reliable global water environment monitoring.关键词:KAN network;hyperspectral remote sensing reflectance;remote sensing reflectance reconstruction;water quality parameter retrieval;coastal water bodies;water remote sensing reflectance2|0|0更新时间:2026-02-13
摘要:To address the challenges in acquiring hyperspectral remote sensing reflectance (Rrs) data and the limitations of existing spectral reconstruction methods, including their reliance on in-situ measurements, weak generalization ability, and insufficient accuracy in optically complex coastal waters, this study proposes a novel deep learning model based on the Kolmogorov-Arnold Network (KAN). The model is designed to directly exploit widely available multispectral satellite observations to efficiently reconstruct continuous hyperspectral Rrs that closely match the characteristics of true measurements, thereby overcoming the bottlenecks of traditional approaches and improving remote sensing inversion performance in complex nearshore environments.The proposed method adopts an end-to-end nonlinear modeling framework within the KAN architecture, incorporating learnable nonlinear activation functions to flexibly capture complex local nonlinear relationships in the input data. This approach enables accurate reconstruction of continuous hyperspectral Rrs from multispectral inputs, with spectral distributions highly consistent with actual observations. In this work, Level-2 Rrs products from the Hyperspectral Imager for the Coastal Ocean were used as training samples. These products were resampled in accordance with the spectral response functions of six mainstream multispectral sensors (S3A OLCI, MERIS, MODIS, SeaWiFS, S2A MSI, and OLI) to generate “multispectral-hyperspectral” data pairs for model training. The approach eliminates the need for in-situ or optical simulation data, relying solely on remote sensing observations for training and modeling, thus greatly enhancing model generality and practicality.Experimental results demonstrate that the KAN model achieved superior reconstruction accuracy (mean R2 > 0.9982) and robustness across all six sensors compared with benchmark models. It not only reproduced the overall spectral shape with high fidelity but also exhibited strong detail-capturing capability in critical regions with missing or sparse sensor bands, such as the red-edge region beyond 680 nm, producing reconstructed curves nearly identical to the original spectra. In downstream chlorophyll-a inversion applications, the use of KAN-reconstructed data significantly improved retrieval accuracy over original multispectral inputs, reducing RMSE by approximately 16.13% and increasing R2 by 3.30%. The advantages were particularly evident in high-concentration waters, effectively overcoming the limitations of multispectral sensors.Overall, the proposed KAN-based hyperspectral Rrs reconstruction model successfully breaks the dependency bottleneck of traditional methods on in-situ or simulated data, offering a highly accurate and generalizable universal solution. By generating high-quality continuous spectra from existing multispectral datasets, it substantially enhances the performance and accuracy of water quality parameter retrieval in complex aquatic environments. The model serves as a powerful data augmentation tool for aquatic remote sensing and a novel technical pathway for leveraging vast archives of historical multispectral satellite data to enable reliable global water environment monitoring.关键词:KAN network;hyperspectral remote sensing reflectance;remote sensing reflectance reconstruction;water quality parameter retrieval;coastal water bodies;water remote sensing reflectance2|0|0更新时间:2026-02-13 - “在深度学习领域,专家提出基于扩散模型的遥感影像数据增强算法,解决了样本稀缺和不均衡问题,显著提升模型检测准确性及跨数据集适应性,为小样本遥感考古目标识别提供技术支撑。”
 摘要:Deep learning-based object detection has become an important tool for large-scale burial site identification in remote sensing archaeology, with its performance highly dependent on sufficient and diverse annotated datasets. However, in practical archaeological applications, acquiring large-scale, high-quality samples is both expensive and time-consuming. Moreover, burial sites are often distributed across highly heterogeneous environments, leading to significant environmental imbalance within datasets. Under few-shot conditions, models tend to overfit to dominant background features and exhibit limited cross-scene generalization capabilities. This study aims to develop an environment-semantic data augmentation strategy that expands background diversity while preserving the original spatial structure and label distribution of burial targets. By simulating multiple environmental contexts through generative modeling, the proposed method can alleviate sample imbalance to a certain extent, enhance robustness to environmental variations, and improve cross-domain transferability, thereby providing a practical and scalable solution for few-shot remote sensing archaeological detection.This study proposes a diffusion-based environment-semantic augmentation framework consisting of three components: environmental generation, fractal fusion, and random enhancement. A pre-trained InstructPix2Pix diffusion model is guided by predefined environmental prompts to simulate burial sites under diverse background conditions while preserving structural features. To further enhance robustness, fractal patterns are fused with images using a Beta-distribution-based weighted multiplication strategy, allowing texture-level enhancement without occluding targets. Additional random image operations are applied to increase variability.The method was evaluated on a self-constructed Altai burial dataset using multiple object detection models, with Mosaic, MixUp, and DiffuseMix serving as baselines. A WorldView-2 dataset was used for cross-domain testing.The proposed method consistently improved detection performance across various models. Compared with Mosaic, the average AP50 across the model ensemble increased by 7.4% on the test set and 12.2% on the validation set, with AP50-95 achieving a maximum improvement of 19.1%. In transfer tasks on heterogeneous datasets, AP50 improved by 16.4%, outperforming both MixUp and DiffuseMix.Through environment-semantic augmentation, the method mitigated background variations across diverse natural environments and enhanced the model’s capability to discern burial targets. Transfer experiments on WorldView-2 imagery further demonstrated that the approach improves model generalization and prevents excessive focus on background features.This study presents an environment-semantic augmentation framework that integrates diffusion-based background simulation with fractal texture fusion for remote sensing archaeological detection. By enriching environmental diversity while preserving target structure, the proposed approach effectively addresses few-shot learning, environmental imbalance, and overfitting issues that commonly limit archaeological object detection models.Experimental results across multiple detection architectures and heterogeneous datasets demonstrate significant improvements in accuracy, recall, robustness, and cross-dataset generalization. The findings confirm that generative models, when properly guided by environmental semantics, can provide meaningful and controllable data diversity for small-sample scenarios.关键词:deep learning;ancient tomb detection;data augmentation;diffusion model;remote sensing archaeology;few-shot learning;environmental semantic enhancement2|0|0更新时间:2026-02-13
摘要:Deep learning-based object detection has become an important tool for large-scale burial site identification in remote sensing archaeology, with its performance highly dependent on sufficient and diverse annotated datasets. However, in practical archaeological applications, acquiring large-scale, high-quality samples is both expensive and time-consuming. Moreover, burial sites are often distributed across highly heterogeneous environments, leading to significant environmental imbalance within datasets. Under few-shot conditions, models tend to overfit to dominant background features and exhibit limited cross-scene generalization capabilities. This study aims to develop an environment-semantic data augmentation strategy that expands background diversity while preserving the original spatial structure and label distribution of burial targets. By simulating multiple environmental contexts through generative modeling, the proposed method can alleviate sample imbalance to a certain extent, enhance robustness to environmental variations, and improve cross-domain transferability, thereby providing a practical and scalable solution for few-shot remote sensing archaeological detection.This study proposes a diffusion-based environment-semantic augmentation framework consisting of three components: environmental generation, fractal fusion, and random enhancement. A pre-trained InstructPix2Pix diffusion model is guided by predefined environmental prompts to simulate burial sites under diverse background conditions while preserving structural features. To further enhance robustness, fractal patterns are fused with images using a Beta-distribution-based weighted multiplication strategy, allowing texture-level enhancement without occluding targets. Additional random image operations are applied to increase variability.The method was evaluated on a self-constructed Altai burial dataset using multiple object detection models, with Mosaic, MixUp, and DiffuseMix serving as baselines. A WorldView-2 dataset was used for cross-domain testing.The proposed method consistently improved detection performance across various models. Compared with Mosaic, the average AP50 across the model ensemble increased by 7.4% on the test set and 12.2% on the validation set, with AP50-95 achieving a maximum improvement of 19.1%. In transfer tasks on heterogeneous datasets, AP50 improved by 16.4%, outperforming both MixUp and DiffuseMix.Through environment-semantic augmentation, the method mitigated background variations across diverse natural environments and enhanced the model’s capability to discern burial targets. Transfer experiments on WorldView-2 imagery further demonstrated that the approach improves model generalization and prevents excessive focus on background features.This study presents an environment-semantic augmentation framework that integrates diffusion-based background simulation with fractal texture fusion for remote sensing archaeological detection. By enriching environmental diversity while preserving target structure, the proposed approach effectively addresses few-shot learning, environmental imbalance, and overfitting issues that commonly limit archaeological object detection models.Experimental results across multiple detection architectures and heterogeneous datasets demonstrate significant improvements in accuracy, recall, robustness, and cross-dataset generalization. The findings confirm that generative models, when properly guided by environmental semantics, can provide meaningful and controllable data diversity for small-sample scenarios.关键词:deep learning;ancient tomb detection;data augmentation;diffusion model;remote sensing archaeology;few-shot learning;environmental semantic enhancement2|0|0更新时间:2026-02-13 - “介绍了其在城市规划与管理领域的研究进展,相关专家提出了一种基于开源兴趣面AOI和兴趣点POI功能标签,联合开放地图OSM与哨兵二号影像自动提取纯净和混合功能样本的方法,并利用ResNet34模型实现街区功能识别,为提升土地利用效率和理解城市功能多样性提供了新思路。”
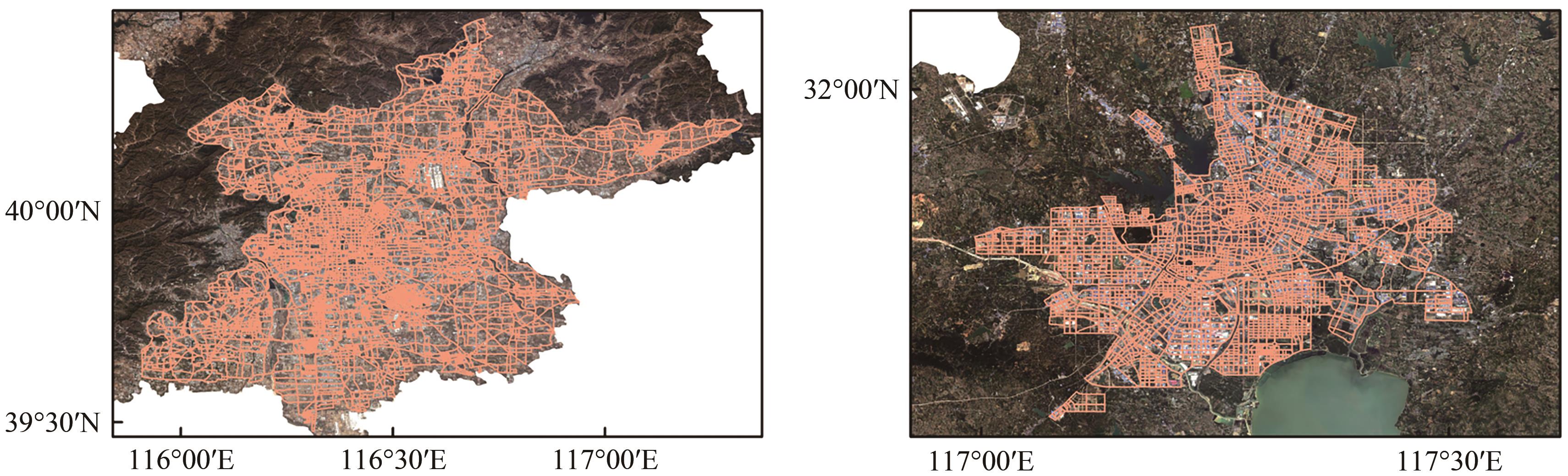 摘要:The identification of the functions of urban blocks serves as a crucial foundation for urban planning and management. With the acceleration of urbanization, the division of single-function zones can no longer adequately meet the demands of complex urban spaces. The identification of mixed-function blocks, as a manifestation of multifunctional urban integration—particularly their automated identification—, holds significant importance for understanding urban functional diversity and enhancing land use efficiency. Against this backdrop, this study proposes an automated sample extraction method for seven categories, including both pure and mixed use, by integrating single functional information derived from area of interest (AOI) and point of interest (POI) data, along with OpenStreetMap and Sentinel-2 imagery. The ResNet34 model is then employed to achieve functional identification for each street block.First, the information entropy of POI distribution is utilized to distinguish between single- and mixed-use street blocks, forming the initial sample set. Subsequently, a multiview discrepancy learning module, based on Sentinel-2 imagery and single-function samples, is designed to further extract samples for single- and mixed-use categories. Given the scale discrepancy between AOIs and actual urban blocks, the abovementioned automated sample extraction scheme is applied to AOI and street block units to enhance sample quantity and scale diversity.The proposed automatic classification method achieved overall accuracies of 72.9%, 78.3%, 73.4%, and 75.1% in Beijing, Hefei, Weifang, and Chengdu, respectively. Compared with the approach using POI distribution entropy solely, the combined use of AOI and POI data improved the recognition accuracy for mixed-function categories by 7%, 18%, 20%, and 13% in these four cities.These results demonstrate the feasibility and effectiveness of the proposed method across diverse urban environments, as well as the potential of integrating crowdsourced geographic data and remote sensing imagery in urban functional zone studies—particularly in the context of mixed-use urban functional zones.关键词:mixed-use street block;Sentinel-2 imagery;deep learning;POI;AOI;urban function zone;multi-view learning0|0|0更新时间:2026-02-13
摘要:The identification of the functions of urban blocks serves as a crucial foundation for urban planning and management. With the acceleration of urbanization, the division of single-function zones can no longer adequately meet the demands of complex urban spaces. The identification of mixed-function blocks, as a manifestation of multifunctional urban integration—particularly their automated identification—, holds significant importance for understanding urban functional diversity and enhancing land use efficiency. Against this backdrop, this study proposes an automated sample extraction method for seven categories, including both pure and mixed use, by integrating single functional information derived from area of interest (AOI) and point of interest (POI) data, along with OpenStreetMap and Sentinel-2 imagery. The ResNet34 model is then employed to achieve functional identification for each street block.First, the information entropy of POI distribution is utilized to distinguish between single- and mixed-use street blocks, forming the initial sample set. Subsequently, a multiview discrepancy learning module, based on Sentinel-2 imagery and single-function samples, is designed to further extract samples for single- and mixed-use categories. Given the scale discrepancy between AOIs and actual urban blocks, the abovementioned automated sample extraction scheme is applied to AOI and street block units to enhance sample quantity and scale diversity.The proposed automatic classification method achieved overall accuracies of 72.9%, 78.3%, 73.4%, and 75.1% in Beijing, Hefei, Weifang, and Chengdu, respectively. Compared with the approach using POI distribution entropy solely, the combined use of AOI and POI data improved the recognition accuracy for mixed-function categories by 7%, 18%, 20%, and 13% in these four cities.These results demonstrate the feasibility and effectiveness of the proposed method across diverse urban environments, as well as the potential of integrating crowdsourced geographic data and remote sensing imagery in urban functional zone studies—particularly in the context of mixed-use urban functional zones.关键词:mixed-use street block;Sentinel-2 imagery;deep learning;POI;AOI;urban function zone;multi-view learning0|0|0更新时间:2026-02-13 - “介绍了其在东北黑土区侵蚀沟监测领域的研究进展,相关专家提出了循环自训练框架CSTF,为解决侵蚀沟跨时相提取难题提供了有效方案。”
 摘要:Perennial soil erosion poses a serious threat to the black soil area of Northeast China, and gully erosion is one of its main manifestations. Remote sensing technology has been widely used in the monitoring and management of gully erosion, and considerable labeled historical survey data have been accumulated. However, how to use these historical data to reliably extract gully information from the latest data captured by various sensors at different times remains an urgent technical problem to be solved. Therefore, this study aims to develop an effective method to achieve reliable cross-temporal gully extraction and provide technical support for land protection and management in black soil areas.On the basis of the above objective, this study proposes a cyclic self-training framework (CSTF). It employs an iterative self-training approach to realize reliable cross-temporal gully extraction. In each self-training iteration, an object-level pseudolabel generation strategy is designed to ensure high-quality pseudolabels for the latest data. Additionally, a loss function based on pseudolabel confidence factors is introduced to effectively mitigate the adverse effects of pseudolabel noise.In the experimental section, Huachuan County, Heilongjiang Province, China was selected as the study area, and the following results were drawn: (1) The characteristic differences between historical and current data present significant challenges for cross-temporal extraction tasks. Compared with traditional fully supervised methods, unsupervised domain adaptation methods offer superior performance. Moreover, the self-training methods demonstrate greater robustness than invariant representation learning, thus justifying their use in cross-temporal extraction studies. (2) For self-training methods, the quality of pseudolabels is a critical factor influencing performance. Hence, a series of improvement strategies is proposed, leading to the best results in accuracy assessments and visual interpretation. Specifically, the intersection over union is 7.39% and 7.90% higher than those of the second-best methods in Experiments 1 and 2, respectively. Furthermore, these strategies are shown to be effective, necessary, and compatible, as demonstrated through detailed ablation experiments. Regarding the analysis of algorithm complexity and operational efficiency, the proposed CSTF cannot only ensure accurate extraction results but can also offer high efficiency, meeting the actual monitoring requirements for gully erosion.In conclusion, the proposed CSTF provides robust technical support for cultivated land conservation in black soil regions and offers a promising approach for sustainable land management. Currently, CSTF only deals with the binary classification of erosion gullies and noneroded areas. Future research will expand the framework to recognize gullies at different developmental stages, facilitating refined monitoring and analysis of erosion gullies.关键词:Soil erosion;black soil area of Northeast China;gully erosion;cross-temporal extraction;self-training;object-level pseudo-label generation strategy;pseudo-label credibility factor;pseudo-label noise0|0|0更新时间:2026-02-13
摘要:Perennial soil erosion poses a serious threat to the black soil area of Northeast China, and gully erosion is one of its main manifestations. Remote sensing technology has been widely used in the monitoring and management of gully erosion, and considerable labeled historical survey data have been accumulated. However, how to use these historical data to reliably extract gully information from the latest data captured by various sensors at different times remains an urgent technical problem to be solved. Therefore, this study aims to develop an effective method to achieve reliable cross-temporal gully extraction and provide technical support for land protection and management in black soil areas.On the basis of the above objective, this study proposes a cyclic self-training framework (CSTF). It employs an iterative self-training approach to realize reliable cross-temporal gully extraction. In each self-training iteration, an object-level pseudolabel generation strategy is designed to ensure high-quality pseudolabels for the latest data. Additionally, a loss function based on pseudolabel confidence factors is introduced to effectively mitigate the adverse effects of pseudolabel noise.In the experimental section, Huachuan County, Heilongjiang Province, China was selected as the study area, and the following results were drawn: (1) The characteristic differences between historical and current data present significant challenges for cross-temporal extraction tasks. Compared with traditional fully supervised methods, unsupervised domain adaptation methods offer superior performance. Moreover, the self-training methods demonstrate greater robustness than invariant representation learning, thus justifying their use in cross-temporal extraction studies. (2) For self-training methods, the quality of pseudolabels is a critical factor influencing performance. Hence, a series of improvement strategies is proposed, leading to the best results in accuracy assessments and visual interpretation. Specifically, the intersection over union is 7.39% and 7.90% higher than those of the second-best methods in Experiments 1 and 2, respectively. Furthermore, these strategies are shown to be effective, necessary, and compatible, as demonstrated through detailed ablation experiments. Regarding the analysis of algorithm complexity and operational efficiency, the proposed CSTF cannot only ensure accurate extraction results but can also offer high efficiency, meeting the actual monitoring requirements for gully erosion.In conclusion, the proposed CSTF provides robust technical support for cultivated land conservation in black soil regions and offers a promising approach for sustainable land management. Currently, CSTF only deals with the binary classification of erosion gullies and noneroded areas. Future research will expand the framework to recognize gullies at different developmental stages, facilitating refined monitoring and analysis of erosion gullies.关键词:Soil erosion;black soil area of Northeast China;gully erosion;cross-temporal extraction;self-training;object-level pseudo-label generation strategy;pseudo-label credibility factor;pseudo-label noise0|0|0更新时间:2026-02-13
Intelligent Applications of Remote Sensing
- “利用光学和SAR遥感影像进行建筑高度估计对于理解城市形态和优化城市存量空间具有重要意义。然而,现有的数据集存在诸多局限:由于样本数量较少,难以满足基于深度学习的遥感信息提取需求,样本所覆盖的区域较为有限,无法提供足够的地理多样性和空间特征代表性,特别是针对中国区域的大规模建筑高度数据集尤为缺乏。此外,数据集的开源性不足,限制了其在更广泛的研究中的应用和验证。为解决这些问题,本文构建了一个面向深度学习的基于Sentinel影像的建筑物高度数据集BHDSI(Building Height Estimation Dataset Based on Sentinel Imagery),该数据集涵盖了中国62个城市的中心城区,共有5606个样本,覆盖了城市,农村等场景,是目前中国区域覆盖面积最大的建筑高度数据集。该数据集包含哨兵一号和哨兵二号的遥感影像以及建筑高度的真实值,样本大小是256×256,相比于64×64大小的数据集,为建筑高度估计研究提供了一个重要的补充选择。相比其他数据集,该数据集具有样本数量大、覆盖范围广、可获取性、建筑高度分布合理等特点,能够更好地满足深度学习网络的训练需求。在此基础上,本文采用相同的深度学习网络对BHDSI数据集及其他类似数据集进行了评估,并对比了多个网络使用BHDSI数据集时在建筑高度回归任务中的表现,深入分析了各网络的优劣。结果表明,与其他数据集相比,BHDSI数据集在建筑高度回归任务中的表现更加优异。进一步分析发现,使用BHDSI数据集时,建筑高度较低的区域其估计精度相对较高。此外,U-Net解码器用于建筑高度估计网络训练能够取得更高的精度。综上,BHDSI数据集为未来建筑高度估计领域的研究提供了重要的支持。”
 摘要:Estimating building height using optical and SAR remote sensing imagery is of great significance for understanding urban morphology and optimizing urban space utilization. However, current datasets often suffer from small sample sizes, limited geographic diversity, and a lack of openness, making them insufficient for supporting deep learning-based remote sensing applications—especially for large-scale studies in China. Accurately estimating building heights is critical for understanding urban morphology and optimizing urban stock space, thus necessitating the development of a comprehensive, representative, and accessible dataset. Methods To overcome these issues, this study constructs a building height dataset based on Sentinel imagery for deep learning (Building Height Estimation Dataset Based on Sentinel Imagery, BHDSI), specifically designed for building height regression tasks. The dataset comprises 5,606 samples from the central urban areas of 62 cities across China, making it the largest building height dataset for the country in terms of geographic coverage. It includes Sentinel-1 and -2 imagery along with true building height values, with each sample having a spatial resolution of 256×256 pixels. This dataset provides an important supplementary choice compared with existing datasets with smaller sample sizes, such as 64×64. The dataset encompasses a wide range of scenarios, including urban and rural areas, ensuring effective representation of spatial features. Results Experimental evaluations demonstrate that the BHDSI dataset leads to superior performance in building height regression tasks in comparison with other similar datasets across various deep learning networks. The results indicate that estimation accuracy tends to be high in regions with low building heights. Furthermore, this study determines that using a U-Net decoder structure in the network architecture contributes to enhanced prediction precision, highlighting the importance of decoder design in deep learning-based height estimation. Conclusion The BHDSI dataset significantly advances the field of building height estimation by offering a large-scale, diverse, and high-quality resource tailored for deep learning. Its broad coverage, balanced height distribution, large sample size, and open accessibility make it better suited for training and evaluating deep neural networks than previously available datasets. This study confirms that data quality and network architecture, especially decoder design, play vital roles in improving estimation accuracy, and BHDSI serves as a strong foundation for future research in this domain.关键词:Sentinel imagery;building height;dataset;deep learning;convolutional neural network0|0|0更新时间:2026-02-13
摘要:Estimating building height using optical and SAR remote sensing imagery is of great significance for understanding urban morphology and optimizing urban space utilization. However, current datasets often suffer from small sample sizes, limited geographic diversity, and a lack of openness, making them insufficient for supporting deep learning-based remote sensing applications—especially for large-scale studies in China. Accurately estimating building heights is critical for understanding urban morphology and optimizing urban stock space, thus necessitating the development of a comprehensive, representative, and accessible dataset. Methods To overcome these issues, this study constructs a building height dataset based on Sentinel imagery for deep learning (Building Height Estimation Dataset Based on Sentinel Imagery, BHDSI), specifically designed for building height regression tasks. The dataset comprises 5,606 samples from the central urban areas of 62 cities across China, making it the largest building height dataset for the country in terms of geographic coverage. It includes Sentinel-1 and -2 imagery along with true building height values, with each sample having a spatial resolution of 256×256 pixels. This dataset provides an important supplementary choice compared with existing datasets with smaller sample sizes, such as 64×64. The dataset encompasses a wide range of scenarios, including urban and rural areas, ensuring effective representation of spatial features. Results Experimental evaluations demonstrate that the BHDSI dataset leads to superior performance in building height regression tasks in comparison with other similar datasets across various deep learning networks. The results indicate that estimation accuracy tends to be high in regions with low building heights. Furthermore, this study determines that using a U-Net decoder structure in the network architecture contributes to enhanced prediction precision, highlighting the importance of decoder design in deep learning-based height estimation. Conclusion The BHDSI dataset significantly advances the field of building height estimation by offering a large-scale, diverse, and high-quality resource tailored for deep learning. Its broad coverage, balanced height distribution, large sample size, and open accessibility make it better suited for training and evaluating deep neural networks than previously available datasets. This study confirms that data quality and network architecture, especially decoder design, play vital roles in improving estimation accuracy, and BHDSI serves as a strong foundation for future research in this domain.关键词:Sentinel imagery;building height;dataset;deep learning;convolutional neural network0|0|0更新时间:2026-02-13 - “介绍了其在土地覆盖制图领域的研究进展,相关专家构建了多模态(MSI+SAR)数据集,提出多模型融合框架,为解决土地覆盖制图中数据局限与模型泛化不足问题提供了有效方案。”
 摘要:Land cover mapping is a vital task in Earth observation; it provides fine-scale details of landscape and support many downstream applications like ecology, hydrology, and resource management. However, current land cover mapping faces key challenges such as limited information from single-source data, substantial data heterogeneity, and insufficient generalization capability of individual models.To solve these issues, this study addresses key challenges in land cover mapping by proposing an innovative framework that integrates multimodal remote sensing data with a multimodel deep learning-based framework for collaborative decision-making. This work aims to provide a novel pathway for large-scale high-resolution land cover mapping and support many other downstream applications.In this study, leveraging the spectral characteristics of multispectral imagery (MSI) and the distinct properties of Synthetic Aperture Radar (SAR) data, a complementary multimodal (i.e., MSI+SAR) dataset is constructed as feature input, effectively overcoming the limitations of using a single SAR modality in complex Earth observation scenarios. Moreover, at the model architecture level, a systematic evaluation of the performance differences among seven representative machine learning-based models is conducted. Based on these foundations, a multimodel fusion strategy is further proposed, combining convolutional neural networks (CNNs), vision transformers (ViTs), and a hybrid CNN/ViT architecture (represented by FCN, ConViT, and CoAtNet, respectively). These three models have demonstrated outstanding performance in previous comparative experiments between multimodal (i.e., SAR+MSI) data and single-modal SAR data.In the experimental section, we conduct a comprehensive evaluation in the entire Beijing City. Remote sensing data are collected from GF-3 (SAR) and GF-6 (MSI). On the basis of these multimodal data, we compare six advanced semantic segmentation models and one pixel-based classification model. Results show that compared with using single SAR data, the utilization of multimodal data significantly improves two key evaluation metrics used in semantic segmentation task or land cover mapping task—Overall Accuracy (OA) and Frequency-Weighted Intersection over Union (FWIoU)—in Beijing City. The proposed multimodel fusion framework further enhances performance in OA and FWIoU, validating the effectiveness of the method in semantic segmentation tasks with multimodal remote sensing data.This paper presents an innovative approach that enhances a model’s capability to extract complex land cover features by effectively integrating multimodal remote sensing data (MSI and SAR) with a multimodel fusion framework. The proposed method demonstrates superior performance in large-scale land cover mapping, achieving significant improvements in classification accuracy and robustness compared with conventional single-source or -model approaches. The success of this framework highlights the powerful potential of multimodal data fusion and collaborative deep learning in overcoming challenges such as spectral ambiguity, cloud interference, and limited labeled samples.关键词:land-cover mapping;multi-spectral;synthetic aperture radar;multi-modal;multi-model fusion;convolutional neural networks;vision transformers2|0|0更新时间:2026-02-13
摘要:Land cover mapping is a vital task in Earth observation; it provides fine-scale details of landscape and support many downstream applications like ecology, hydrology, and resource management. However, current land cover mapping faces key challenges such as limited information from single-source data, substantial data heterogeneity, and insufficient generalization capability of individual models.To solve these issues, this study addresses key challenges in land cover mapping by proposing an innovative framework that integrates multimodal remote sensing data with a multimodel deep learning-based framework for collaborative decision-making. This work aims to provide a novel pathway for large-scale high-resolution land cover mapping and support many other downstream applications.In this study, leveraging the spectral characteristics of multispectral imagery (MSI) and the distinct properties of Synthetic Aperture Radar (SAR) data, a complementary multimodal (i.e., MSI+SAR) dataset is constructed as feature input, effectively overcoming the limitations of using a single SAR modality in complex Earth observation scenarios. Moreover, at the model architecture level, a systematic evaluation of the performance differences among seven representative machine learning-based models is conducted. Based on these foundations, a multimodel fusion strategy is further proposed, combining convolutional neural networks (CNNs), vision transformers (ViTs), and a hybrid CNN/ViT architecture (represented by FCN, ConViT, and CoAtNet, respectively). These three models have demonstrated outstanding performance in previous comparative experiments between multimodal (i.e., SAR+MSI) data and single-modal SAR data.In the experimental section, we conduct a comprehensive evaluation in the entire Beijing City. Remote sensing data are collected from GF-3 (SAR) and GF-6 (MSI). On the basis of these multimodal data, we compare six advanced semantic segmentation models and one pixel-based classification model. Results show that compared with using single SAR data, the utilization of multimodal data significantly improves two key evaluation metrics used in semantic segmentation task or land cover mapping task—Overall Accuracy (OA) and Frequency-Weighted Intersection over Union (FWIoU)—in Beijing City. The proposed multimodel fusion framework further enhances performance in OA and FWIoU, validating the effectiveness of the method in semantic segmentation tasks with multimodal remote sensing data.This paper presents an innovative approach that enhances a model’s capability to extract complex land cover features by effectively integrating multimodal remote sensing data (MSI and SAR) with a multimodel fusion framework. The proposed method demonstrates superior performance in large-scale land cover mapping, achieving significant improvements in classification accuracy and robustness compared with conventional single-source or -model approaches. The success of this framework highlights the powerful potential of multimodal data fusion and collaborative deep learning in overcoming challenges such as spectral ambiguity, cloud interference, and limited labeled samples.关键词:land-cover mapping;multi-spectral;synthetic aperture radar;multi-modal;multi-model fusion;convolutional neural networks;vision transformers2|0|0更新时间:2026-02-13
Data Articles
- Postal code:100190
- Tel:010-58887052 Email:nrsb@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备20021838号-9
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0